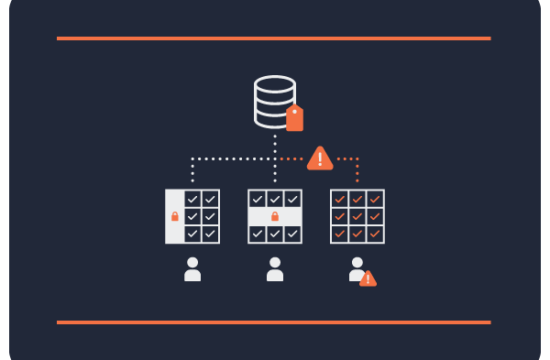
Who needs control?
This blog post continues the topic of Schema Design Best Practices and focuses on the access control view layer. Many of us at Okera have years to decades of IT and data processing backgrounds. Some of us were early Hadoop adopters all the way back to 2007. Initially the clusters were wide open and there was little in regards to access control available. You would use network boundaries and firewalls to restrict access to the data owners. Inside the cluster they could see and do whatever they wanted. And it was OK for the time being as those early users where hands-on and dev-ops savvy, owning the infrastructure and the data, delivering results at their convenience.
Then came the enterprise adoption. Here you find users that just need to use data, and ideally access with tools with which they already are familiar. These companies are not the early adopters with lots of engineers that can hand-hold a single system, but rather the large corporations that are slowly starting their journey to be data centric. Over time the traditional data warehouse architecture has been complemented with big data technologies, such as Hadoop, or more generically, data lakes, streaming systems, and so on. All of them have their own set of access control features that sport their own specific commands for administration; and they provide different audit event logging mechanisms that make correlated events at times impossible to align globally (think enterprise SIEM).
Unified Access Control
This leads to the need of a unified data access solutions, and that is what we at Okera offer. I personally liken this to the last mile problem in telecommunication: you can have the fattest Internet pipe close by, but if your house is connected through a decades old copper wire, you will most likely not be able to make use of the fast uplink. You are bottlenecked getting data. And that is what happens without a unified data access layer, you will not get the data you need, or not fast enough.
The Okera Platform does much more than just unifying access and its control mechanisms, but for this post we focus on how to enable users to access the data they need. For starters, in Okera you can delegate responsibility in an hierarchical manner so that groups of users can have their own database administrator (DBA) that can manage datasets for the regular users.
Schema Design
We recommend DBAs to follow our schema design best practices, which organizes the various dataset related tasks into layers. The lowest layer maps the raw data from their storage location into our registry as a base table. On top of that we recommend views that disconnects the user from the base tables, and which can be used to clean up issues and bring the dataset in line with corporate standards.The DBA should also use an access control view to implement any filtering or masking that needs to take place for users to see their expected results.
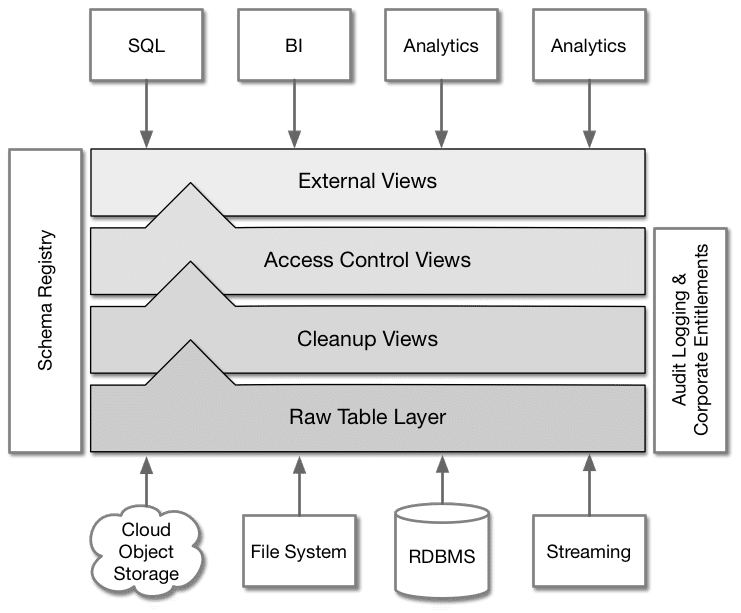
The DBA should also use an access control view to implement any filtering or masking that needs to take place for users to see their expected results.
Access Control
Okera provides the commands to create roles which are then granted privileges, such as read access to a dataset. We also provide a set of built-in functions that can be used to further implement more complex access scenarios, which are evaluated at query time. Using the basic RBAC mechanisms, you can define roles and views, and subsequently grant access as necessary.
For example, you can create a base table and directly grant access to it.
CREATE ROLE analyst_role; GRANT ROLE analyst_role TO GROUP analysts; [/pythom] Example: Create a role and assign it to a user group [python] CREATE EXTERNAL TABLE salesdb.transactions_raw( txnid BIGINT, dt_time STRING, sku STRING, userid INT, price FLOAT, creditcard STRING, ip STRING, region STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY "," LOCATION "s3://acme-data/sales/transactions"; GRANT SELECT(txnid, dt_time, sku, price) ON TABLE salesdb.transactions_raw TO ROLE analyst_role'; # Not recommended!
Example: Create a base table over files in S3 and grant limited access to it
But this is not what we recommend you do. Instead, define a (optional) cleanup and access control view over it. Having a view gives you the freedom to also apply any transformations necessary to change the result of the table, based on the group a user belongs to. For instance, you can use the Okera provided has_access() function to check a related resource, like the underlying dataset. Combined with the SQL if() function, you can dynamically return the original column value or an obfuscated version of it.
CREATE VIEW salesdb.transactions AS
SELECT
txnid,
dt_time,
sku,
if (has_access('salesdb.transactions_raw'), userid, tokenize(userid)) as userid,
price,
if (has_access('salesdb.transactions_raw'), creditcard,mask_ccn(creditcard)) as creditcard,
if (has_access('salesdb.transactions_raw'), ip, cast(tokenize(ip) as STRING)) as ip,
region
FROM salesdb.transactions_raw;
GRANT SELECT ON TABLE salesdb.transactions TO ROLE analyst_role;
Example: Create an access control that filters based on access rights to the base table
This is useful for some use-cases, but not for all of them. Sometimes you need to filter based on the user instead.
CREATE VIEW salesdb.transactions AS SELECT txnid, dt_time, sku, if (user() = "admin", userid, tokenize(userid)) AS userid, price, if (user() = "admin", creditcard, mask_ccn(creditcard)) AS creditcard, if (user() = "admin", ip, cast(tokenize(ip) AS STRING)) AS ip FROM salesdb.transactions_raw; GRANT SELECT ON TABLE saledb.transactions TO ROLE analyst_role;
Example: Create a view that masks data based on the user accessing it
It may be obvious from the example, but using this approach would require a view for each user that you want to filter on. Instead, we recommend that you use the has_roles() function and make decision based on the role instead.
CREATE VIEW salesdb.transactions AS
SELECT
txnid,
dt_time,
sku,
if (has_roles('sales_admins'), userid, tokenize(userid)) AS userid,
price,
if (has_roles('sales_admins'), creditcard, mask_ccn(creditcard)) AS creditcard,
if (has_roles('sales_admins'), ip, cast(tokenize(ip) AS STRING)) AS ip
FROM salesdb.transactions_raw;
Example: Create a view that filters based on roles
Using roles makes the query slightly more useful, but still is not ideal. Where the has_roles() really helps is in selections. For example, you can combine the above view with another that filters out rows that are outside of the roles region.
CREATE VIEW salesdb.sales_per_region AS
SELECT * FROM salesdb.transactions
WHERE has_roles('de_role') AND region = 'de' OR
has_roles('gbr_role') AND region = 'gbr';
Example: Create a view that selects subsets of rows based on roles and regions
Both built-in functions are very powerful and give DBAs control over what is returned to specific users. What you may note though is that you need to create a boolean predicate for every role/region combination, making the view definition more static and more cumbersome in maintenance. This leads us to our last part of access control.
Advanced Functionality
Finally, there is more you can do using these access control functions. Continuing from our last example, you can make use of column values to dynamically filter data. In our example schema we have a column named region, which includes a country code. We can make use of that fact and filter rows based on roles that match those regions.
CREATE ROLE de; CREATE ROLE gbr; CREATE VIEW salesdb.sales_per_region AS SELECT * FROM salesdb.transactions WHERE has_roles(lower(region));
Example: Create a view that filters rows on column-based values
All the DBA now has to do is allow access by assigning the matching role to the respective user group.
GRANT ROLE de TO GROUP analysts_de;
Since we have combined the two access control views, we also get the masking functionality as well.
presto> select * from jdbc_demo.sales_per_region limit 5; txnid | dt_time | sku | userid | price | creditcard | ip | region ------+---------------------+-------+--------+-------+---------------------+----------------------+-------- 483 | 08/21/2016 09:49 AM | sku87 | 82364 | 810.0 | XXXX-XXXX-XXXX-6331 | -8418315997702349334 | DE 579 | 06/15/2016 05:05 AM | sku52 | 59072 | 400.0 | XXXX-XXXX-XXXX-5804 | -5706330635178565995 | DE 948 | 05/16/2016 02:05 PM | sku73 | 34515 | 670.0 | XXXX-XXXX-XXXX-2537 | 2315370975016102511 | DE 1465 | 03/17/2016 04:18 AM | sku50 | 46605 | 250.0 | XXXX-XXXX-XXXX-5932 | 2326400379827501408 | DE 2137 | 11/05/2016 07:23 AM | sku06 | 20626 | 540.0 | XXXX-XXXX-XXXX-9349 | -5031361145655993176 | DE (5 rows) Query 20180817_133516_00001_iixrd, FINISHED, 1 node Splits: 18 total, 18 done (100.00%) 0:01 [1.95K rows, 0B] [1.47K rows/s, 0B/s]
Example: Querying the final view shows the filtering and masking in action
This is a very powerful feature, where a single view is now serving all users of a company, while dynamically filtering and masking as necessary. This mitigates the need for many complex views that would otherwise be necessary.
Our entire team at Okera is hard at work to extend on the already provided functionality. We are looking forward to working with you in solving your data access problems. If in doubt, please reach out to us so that we can discuss your issues and find suitable solutions.