Over the last three years, we’ve helped our customers build and manage their data lakes. Some of them have just started their data lake journey, while others have large data lake environments with complex datasets that contain sensitive information.
Two sets of questions came up again and again:
- How is data in the data lake being consumed – by which users and through which applications? Do I have any large, expensive datasets that are not being used? How are these patterns changing over time?
- Where is the sensitive data in the data lake, and do my access control policies work to protect it? How is sensitive data being consumed? As the contents of the lake and number of users evolve, are my policies still foolproof?
Building the Data Lake
Let’s say an enterprise is just starting to build their data lake, and they’ve decided not to put any sensitive data into the lake yet. What that data lake owner needs is something to verify that sensitive data wasn’t accidentally ingested. If they find that it was, the next step could be just to delete it.
Additionally, when getting started with onboarding users to a data lake, the data lake owner wants to make sure their users are successful. Knowledge of how users are adopting the platform and which tools are being adopted the quickest can help immensely.
Growing the Data Lake
On the other hand, an enterprise that knows they have sensitive data in their lake and has set up access policies would use the same tool to verify the policies are correct, current, and the principles of least privilege are being enforced. The next step for them could be a policy audit.
As the data lake grows in users and size, the data lake owner will want to optimize the datasets for cost and performance. Large, frequently accessed datasets can be rewritten to make them more efficient to query. Unused datasets can be deleted or archived, and redundant copies can be purged. Understanding usage patterns is critical to guide and prioritize these actions.
What do Data Lake Owners Need?
All data lake owners desire to improve the lake – whether by making it more secure and compliant, optimizing for performance and cost, or helping data consumers be successful by onboarding new applications and datasets. This need is independent of the maturity and current adoption of the lake.
Data lakes are fundamentally designed to change over time; one of their key benefits is the ability to handle evolving data and query patterns. That means the solution must be robust for a changing environment, able to run without interruption, and have the flexibility to answer a variety of questions.
That is exactly what we built with Okera Spotlight, our newest product designed to arm data platform owners with the insights they need to take action to improve the data lake.
Okera Spotlight: How it Works
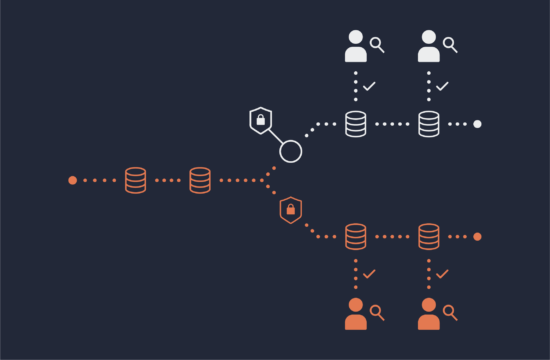
Okera Spotlight consumes the audit from AWS CloudTrail, which captures audit to all Amazon S3 activity across all applications with no impact to the existing access patterns
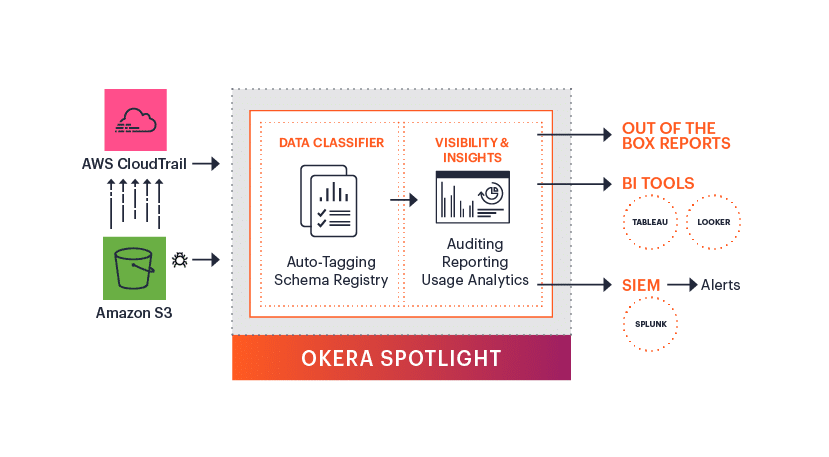
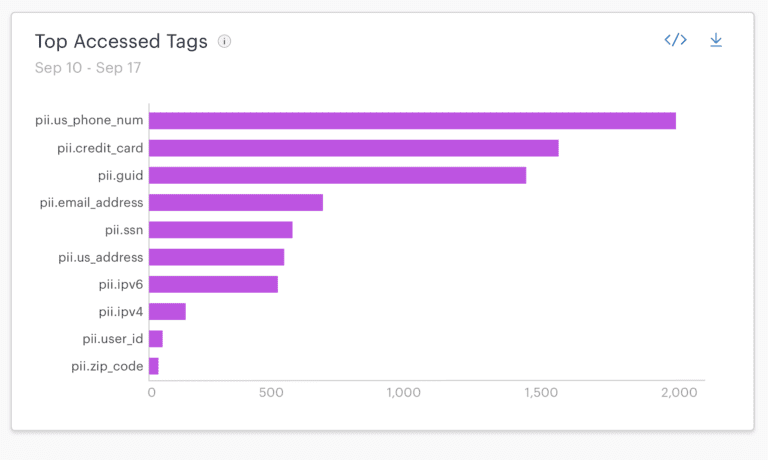
It then combines the audit activity with automatically extracted metadata such as schemas, applies rules to identify sensitive content, and produces an enriched audit trail. (Users can also create their own tags if desired.)
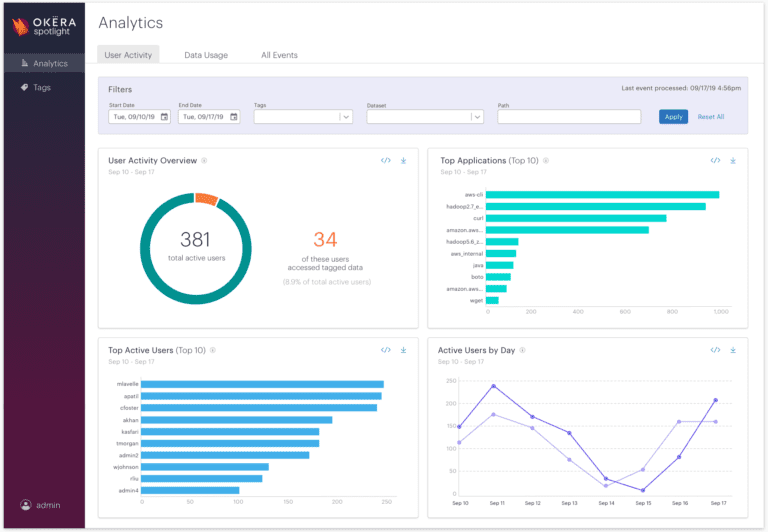
Our built-in reports answer common business questions like top active users, top accessed datasets, and top applications. The enriched audit trail is also made available for further analysis with common BI tools, or to integrate with SIEM tools to alert on improper or unexpected access patterns.
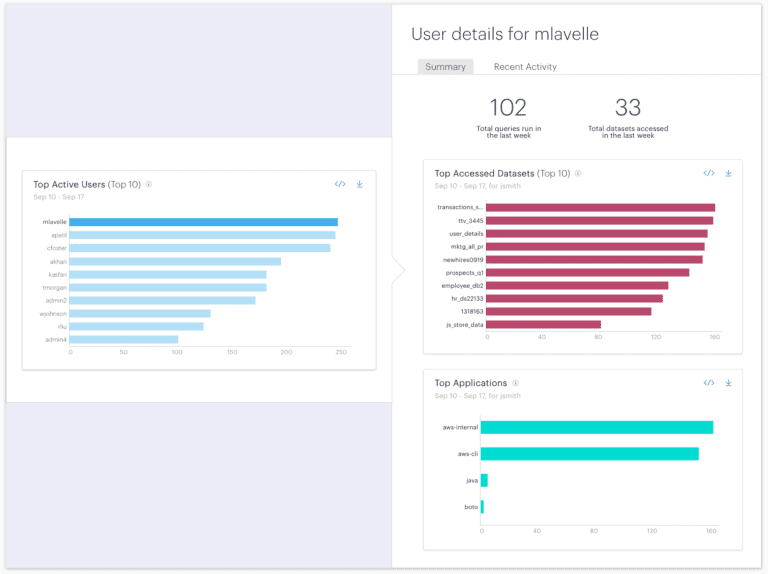
Okera Spotlight is designed to run in your environment with minimal dependencies. Users can set up and get the system running in under an hour.
Our Vision
Okera’s goal is to help enterprises build a data platform that is secure and well-governed but at the same time support the business and the data users. We want enterprises to have the tools to balance data privacy with business efficiency.
From all of our experience, we understand this is an iterative process and that successful platforms can evolve seamlessly with the business’s needs. Okera Spotlight is designed exactly for this: to focus on what to improve next and to help make the data lake successful as quickly as possible.
![]()