How to Comply
with GDPR
Solving Technical Data Access Governance Challenges with Okera

What is GDPR?
The GDPR was designed to regulate data controllers, which is defined as any organization collecting and/or processing data from EU residents that is ultimately responsible for the safekeeping of that data. Under the GDPR, controllers must immediately report any data breaches, and they also must architect the entire IT infrastructure and application development with a focus on privacy by design.
In May of 2018, the General Data Protection Regulation (GDPR) went into effect for the European Union (EU). If you’re reading this from somewhere outside of the EU and happen to be providing an online service and have customers in one of the EU member countries, then you should be concerned. Not complying with the GDPR rules has resulted in steep penalties, ranging into the millions of Euro.
A quick search will yield countless articles and blog posts that discuss the key requirements of the GDPR, so we will refrain from repeating them here. Instead, we’ll focus on two of the main technical hurdles that an international enterprise has to overcome in order to be compliant:
- Pseudonymization
- Opting In and the Right to be Forgotten
Note: While these two technical requirements may have originated here, they have become part of many new privacy laws that have been passed since, such as California’s CCPA (California Consumer Privacy Act) that went into effect January of 2020, and Brazil’s newly passed GDPL (General Data Protection Law).
The Rise of Big Data
The advantage of designing an entire infrastructure around privacy by design is that every layer in your technology stack, both hardware, and software, will have current and future security best practices in mind. What works against this idea in practice is that most risk-averse large enterprises, rather than “betting on one horse,” use an abundance of storage technologies and software systems. It is common for different teams to use a variety of technologies in an attempt to fulfill the promise of the unreasonable effectiveness of data.
Today, a single person can produce so many tangible data points – think smart devices and always connected computers – that we had to build new, equally limitless forms of storage in order to cope with all of that data. Now there are Hadoop clusters (both cloud-based and on-premises), distributed file and object storage systems that consume any signal available from commercial sources (such as weather data, social media graphs), and customers/users (for instance, clickstream or sales data) alike.
GDPR states that a subject — a person or entity whose data is stored by an organization — has the right to know what data about them is being stored. They must provide explicit consent for a controller to use their data, and can choose to revoke consent at any time.
You can see how the management of these rules across all the different storage systems would quickly become an organizational nightmare; in practice, it is highly prone to errors. And unfortunately, there’s not even an obvious solution. Some try locking up most, if not all, of their data, although doing so renders it pretty much useless for analytics and insights — even for use cases that are inherently compliant with GDPR guidelines.
Pseudonymization
One requirement of GDPR is the anonymization of Personally Identifiable Information (PII) data. This includes the tokenization of data to obfuscate information that could be used to identify subjects, even without any other data. GDPR recognizes that pseudonymization is not without limitations and therefore still considers this data to be personal. But pseudonymization is still a key technique for responsible data usage; after all, why give someone access to data that they don’t actually need?
Typically, implementing pseudonymization in a heterogeneous Big Data architecture meant performing Extract, Transform, and Load (ETL) jobs to save multiple copies. Say, for example, there is a certain dataset containing PII that the organization would like to share with multiple teams. IT would have to create a copy with specific data redacted. This approach not only creates unnecessary I/O traffic; you now have a nearly identical copy of this dataset, which must be stored and managed. The result is the consumption of more resources and an additional layer of administration in order to ensure the copied dataset remains valid over time.
Okera solves this dilemma by reading the uncurated dataset and applying ad-hoc transformations based on the user’s roles. In most existing systems, users either have access to all of the data or none of it. With Okera, you can create advanced access policies that apply on-the-fly transformations to provide only the information needed at that time, as shown in the following example:
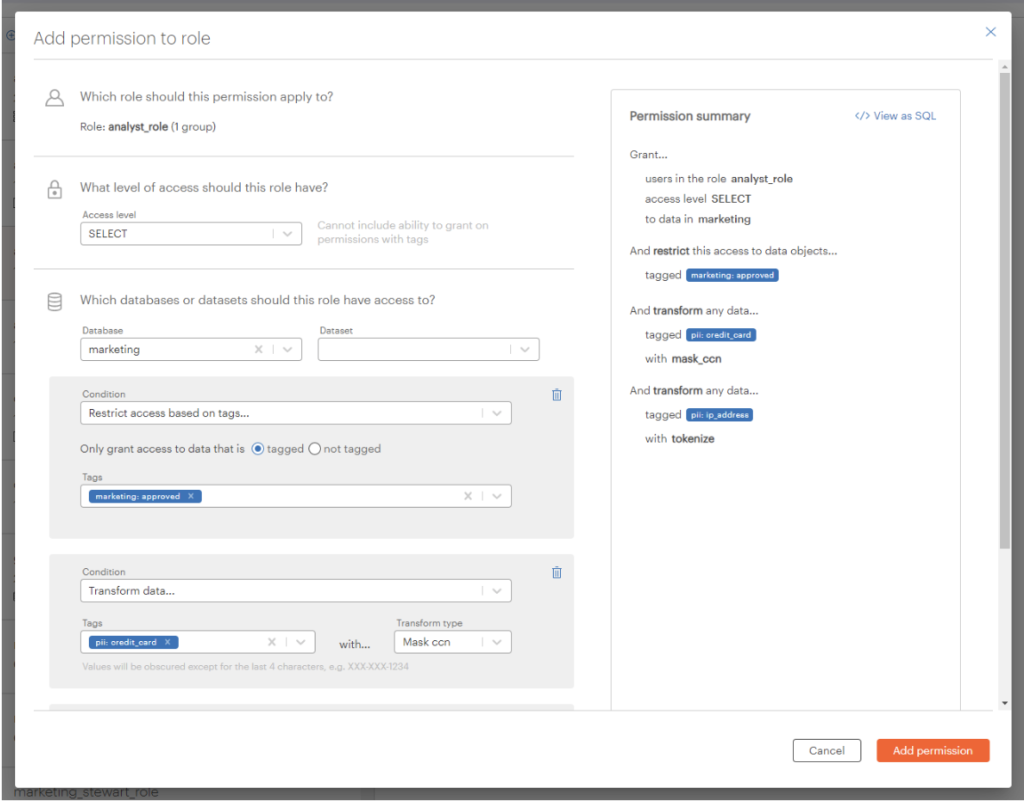
The screenshot shows a simple yet powerful policy that applies to tagged resources in the Metadata Registry. Clicking on the “View as SQL” button reveals the underlying SQL statement to create the policy:
GRANT SELECT ON DATABASE `marketing`
HAVING ATTRIBUTE IN (`marketing`.`approved`)
TRANSFORM pii.credit_card WITH `mask_ccn`()
TRANSFORM pii.ip_address WITH `tokenize`()
TO ROLE `analyst_role`;
What is happening here is that this policy will apply to all users that are assigned the “analyst_role”, and it enforces the following:
- Analysts will have read access to all datasets in the “marketing” database, unless the dataset is NOT tagged with “marketing.approved”
- All columns tagged with “pii.credit_card” will have their values masked up to the last four digits
- All columns tagged with “pii.ip_address” will have their values tokenized
For example, when querying the data as the analyst that has the above policy assigned and using a dataset where the “creditcardnumber” column has been tagged with the matching “pii.credit_card” tag etc., you will see the following result:
analyst> SELECT * FROM marketing.user_account_data
[
{
"name": "Warren Reyes",
"phone": "1-622-369-1888",
"email": "auctor.odio@amet.ca",
"userid": "279185A8-9654-7F26-4370-D75390F6DDC8",
"lastlogin": "Sat, 14 Apr 2018 15:44:42 -0700",
"creditcardnumber": "XXXXXXXXXXXXXXX5516",
"location": "-12.63919 -170.65658",
"ipv4_address": "749.130.609.625",
"ipv6_address": "i992:ba4:57t3:8q89:82y2:3h20:t27h:93w3"
}
]
Note how the IP addresses are tokenized, while the credit card number is partially redacted. Okera supports a number of de-identification functions right out of the box, but you can write your own user-defined functions (UDFs) as well.
Opting In and the Right to be Forgotten
In an enterprise environment, PII can reside in an HDFS cluster, an Amazon S3 bucket or Azure ADLS storage account, a relational database, or a combination of all of them at any given time. There may be countless files or tables containing PII on the same individual, strewn across terabytes of data. Combining that with the GDPR requirement of the right to be forgotten, and it can become very expensive to purge data when a user opts out or when consent wasn’t obtained in the first place.
Removing PII is commonly an ETL job that runs every few weeks, maybe once per quarter. But this practice is non-compliant with GDPR, which requires these actions to take effect without undue delay (Article 59 states “…at the latest within one month…”). In addition, the data is still active until removed, which creates an additional process in order to purge, obfuscate, or hide records with PII that should no longer be accessible. This is commonly achieved by applying the following filters against each dataset to produce a GDPR-compliant dataset void of offending data:
- Allow Lists: A list of all record IDs of subjects that have given consent to the use of their data.
- Deny Lists: A list of record IDs of subjects that have opted out of the use of their data.
These lists are used to filter out or allow the inclusion of any matching record. While this approach is not uncommon for data filtration, it expends a non-trivial amount of effort, given the sheer volume of data and many storage locations where PII may reside in most enterprise environments.
The following diagram shows how Okera solves this problem by filtering data on-the-fly:
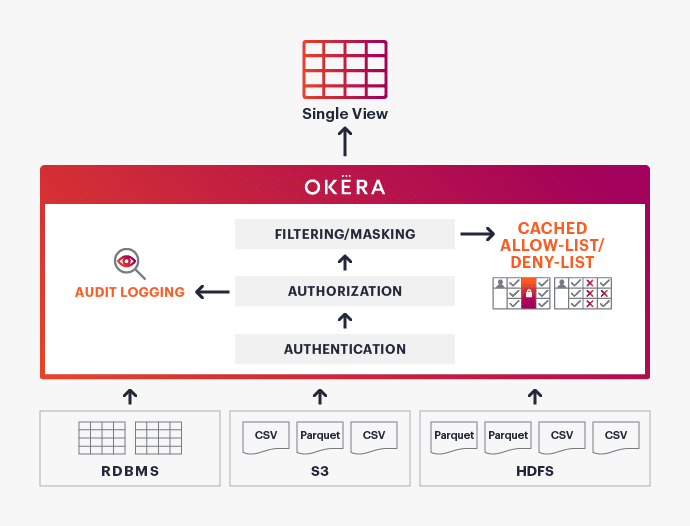
Instead of rewriting data every time that a person gives consent or opts out, the data is filtered on access. Allow or deny lists are used to define which records should be included in the result set.
Okera converts every data source into a table structure, regardless of the original format. Every supported format is read, parsed, and then the catalog-defined schema is applied, allowing higher-level tools to treat each source like a database table. Since each user running a query must first authenticate themself, the context of the query execution is known ahead of time and the matching access policies can be applied as needed as part of the authorization step.
The practice of applying filters on queries is not a new one; DBAs commonly employ database VIEWs, where the VIEW is a SELECT statement that JOINs the main and filter tables, and, using the default INNER JOIN behavior, removes all single-side records in the process. But this doesn’t work for data sources that don’t expose a columnar layout. Okera solves this problem by abstracting every data source as a table, enabling database manipulation functionality on every dataset.
Another complication is that the main and filter tables can be very large, making the JOIN either very expensive or technically infeasible given resource constraints. Okera optimizes cluster resources to cache filter tables, thus making large JOINS not only possible but also efficient enough to be used in recurring operations.
The centralized authentication, authorization, and audit logging of Okera satisfies the GDPR requirement of enforcing explicit consensus for inclusion within a reasonable amount of time. Instead of doing bulk deletes every few weeks or months, you can apply changes on the fly as data is being accessed.
Outlook and Summary
There is an additional advantage of using Okera as a unified access layer over all your data sources: It helps with the GDPR requirement called right of access, which includes the right of subjects to get access to their data. Okera’s unified metadata registry keeps all of the datasets and their details in one place, simplifying the extraction of all records – even from multiple systems – for a given subject.
Okera solves technical GDPR requirements ad-hoc, providing federated access, unified authorization, and audit logging. This simplifies the management of vast amounts of data and streamlines the necessary architecture to allow users and applications to deal with a single point of access.
Security and compliance don’t have to slow you down.
Read now to solve technical challenges in order to comply with GDPR.