One thing I have learned working with Big Data, and Hadoop in particular, over the last thirteen years is that data is truly an important asset of any organization, no matter its size. Any interaction with outside entities (customers, IoT devices, and more) produces data in its raw form, be it clickstream, transactional, or multiple other types of data. It must be ingested upstream and then somehow prepared to be made available to the downstream readers – the developers, analysts, and data scientists who will be transforming the data into business insights that can fuel innovation and growth.
The first part can be considered a solved problem, with many companies providing solutions to bring data reliably into a data lake, whether file- or stream-based. What isn’t so easy is the second part – providing data access in a safe and controlled manner to those who need it.
Data Governance for the Cloud
Data governance is a term that refers to the framework of processes applied to the entire lifecycle of data within an organization. In general, data governance starts when data is ingested and ends when it is deleted, with a wide range of topics in between that includes data cleansing, data curation, data cataloging, data discovery, and data security – the last one being the primary focus of this blog.
But trying to apply data governance, a concept that came about in the age of data warehouses, to more recent Big Data initiatives like the data lake, doesn’t always work on a 1:1 ratio. When dealing with “small” data, you were at liberty to transform data into what was needed for a particular group of users. The classical ETL (the I/O heavy extract, transform and load process) may not be applicable to Big Data, as physics alone nixed this time-consuming preparation step.
Modern systems read data directly from the staged data files after they have been ingested in a viable data lake format such as Parquet and cleansed in the process. With the bring your own engine mantra of the data lake, you now have half a dozen (or more!) downstream applications and compute frameworks reading the data directly from where it resides. Write once, read many is ideal for the immutable but hyper-scalable file and object storage systems of today (HDFS, Amazon S3, Microsoft ADLS Gen1&2, Google GFS).
The Cost of Flexibility
What is the drawback, then? Once more, it is physics, which at scale prohibits the staging of data many times over for each use case. An organization with an organically grown permission system will find the combinatorial challenge alone reason enough not to stage files for every permission combination needed.
Rather, a dynamic access layer needs to apply permission on-the-fly as data is read by an authenticated client. And it is not enough to just make this an all-or-nothing decision based on the client’s level of authorization. If your granularity stops at files, then all you can enforce are file-level permissions, such as Access Control Lists (ACLs). This is not good enough in practice, with clients requiring access on a much more granular level, including row- and column-level permissions.
In addition, granting access to a specific attribute of a relation is, again, an all-or-nothing action. This may suffice in some situations – for example, hiding the column containing credit card numbers from the marketing team. On the other hand, a sales analyst may want to group sales by credit card providers, which is encoded into the first six digits of the card number and remains the same for all owners of a particular card and provider. That is just one instance of personally identifiable information (PII) that holds interesting value, but should not be made available in full to everyone who may want to analyze the data.
Data Masking
This is where data masking comes into play, which is the task of transforming data in such a way that parts of it are modified according to data governance policies. For instance, data obfuscation and data anonymization are techniques to change the content of sensitive fields so as to comply with corporate privacy rules.
Let me show you some examples using the Okera Web UI to enter the commands. (Note that using straight SQL allows us to use the built-in security-related functions without needing to have actual data files. They do work the same way as part of an access control layer, where they act on the values stored in the underlying source system.)
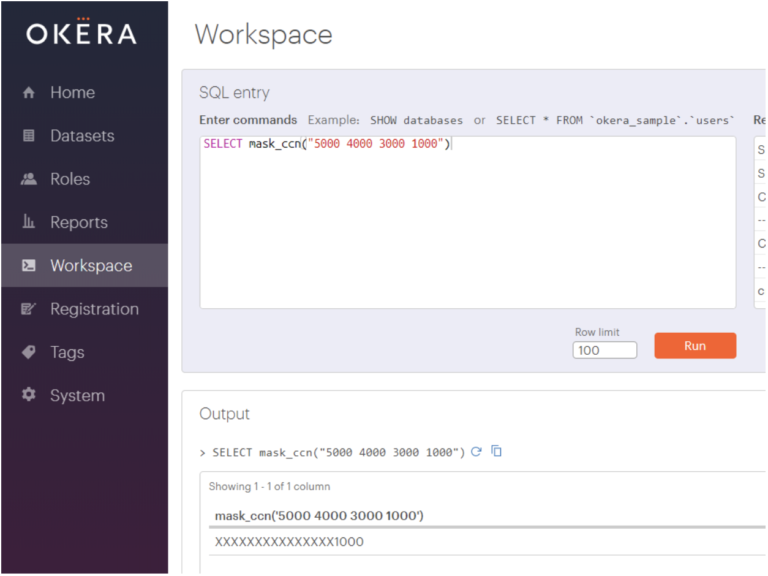
Data Masking
The simplest of our masking functions is mask_ccn(), which takes a credit card number and masks (that is, obfuscates or redacts) the first 12 digits of it.
> SELECT mask_ccn("5000 4000 3000 1000");
XXXXXXXXXXXXXXX1000
If you want to mask a variable part of the value, you can use the mask() function that also takes a start and length parameter.
> SELECT mask("5000400030001000", 7, 13);
500040XXXXXXXXXX
Data Anonymization
The functions in this group will change the value of a field so that it cannot be used anymore. There are variants that fully randomize the value, or use the original value as the seed for the randomization, meaning it will always produce the same random value for a specific original one. This allows you to still join datasets or aggregate records based on a shared value.
> SELECT tokenize("5000 4000 3000 1000");
5512 7744 8063 9850
> SELECT tokenize("5000 4000 3000 1000");
5512 7744 8063 9850
> SELECT tokenize_no_ref("5000 4000 3000 1000");
1013 2461 1514 1969
> SELECT tokenize_no_ref("5000 4000 3000 1000");
9415 6941 3181 2855
Both functions retain the original format of the value, but transform them in a different way; the first one produces the same result for two invocations, while the later is creating different random values.
Another option is to anonymize the value with a non-cryptographic hash function, such as the Jenkins hash. This transforms a value of any length into a fixed size hash that is not reversible, but yields the same result for a given original value.
> SELECT hash("Jane Doe");
-4049133654905739000
This is different from, for instance, data encryption, which uses a symmetric or public key-based scheme to encode a value so that only authorized clients with the matching decryption key can decode it. (Okera also supports encryption, but for the sake of brevity, we won’t show a specific example.)
The functions shown are just a small subset of what Okera offers, but serve as an example for functions with a context that does not exceed the original value of the column itself. In other words, these functions are not able to extend their reach across columns, rows or even tables. They also only produce fixed or random values, which may or may not be sufficient.
Differential Privacy
For more advanced anonymization, we need to look at functions that support something called differential privacy. The goal here is to apply statistical methods to modify content at a larger scope, like at the table level.
Imagine, say, that you need to analyze customer data, but require the birthday in order to group customers by demographics. Randomizing this piece of PII is not a good idea, as it would change the overall composition of data, often making it equally distributed across the possible value range.
Instead, what is needed is a function that changes every birthday so the overall distribution stays nearly the same, but individuals are no longer identifiable. It may mean adding a few days or a few weeks to each date, but is a factor of the number of overall datasets.
Okera offers the diff_privacy() function for that purpose, allowing you to introduce uncertainty, or jitter, into your sensitive data so that the above requirement can be fulfilled. (Again, for brevity’s sake, I will refrain from showing the details of how it works.)
Differential privacy is a hot topic, especially in the context of recent privacy laws like the EU’s GDPR or California’s CCPA. Privacy by design is one of the common building blocks for these regulations, which includes the need to make deanonymization all but impossible. Some topics for further research, if you’re curious, include Epsilon Differential Privacy or k-anonymity. The former uses a budget epsilon to introduce enough uncertainty into the data for privacy’s sake while retaining usability of the data as much as possible.
Even statistical methods are only as good as their sensible application. For instance, given enough access to data, a skilled user could join enough datasets to recreate the original dataset from many modified ones. This would only be detectable by a central layer; whether actively as part of an access control service applied at runtime, or retrospectively as part of an audit event.
Dynamic Data Lake Security
We have discussed in great detail the concept of data masking, which includes obfuscation, redaction, tokenization, and encryption of values, and may happen in the context of multiple datasets joined together. But there is even more to data lake security than just protecting sensitive data values, such as filtering out an entire subset of data based on the user for regulatory purposes.
GDPR introduced the concept of “the right to be forgotten.” Subjects – that is, individuals whose data is stored by third-party organizations – can opt-out of having their data used by the organization for business analytics. Within a few days of someone making the request, the business must comply and remove that person’s data, which poses enormous problems for data lakes at scale (back to physics again, which you cannot cheat).
We at Okera strongly believe this requires a single copy of the data in full fidelity, accessible only by the data producers, with a data access layer that applies transformations across rows, columns, and even whole datasets dynamically, and only where necessary to avoid undue performance penalties. Only then you can untangle the messy permissions spaghetti presented by heterogeneous permission systems, each with their own idiosyncrasies and levels of granularity. One layer allows for the application of differential privacy across all data sources without the risk of unintentional deanonymization (lack of knowledge about what data was joined).
On top of that, one access layer gives you a single audit log for all your access – no need to harmonize logs of different formats and richness to answer immediate and pressing questions during the auditing process. One log equals a single source of truth.
Conclusion
For the restless reader, here are my key takeaways about data obfuscation:
- Anonymization is a spectrum from useless but safe (i.e. randomize every value) to useful but possibly dangerous (i.e. expose PII data).
- Simple approaches that only consider column values in isolation (for example, masking out credit card numbers) are useful only to remove PII or other sensitive data, making data less useful or possibly even useless.
- Statistical data obfuscation considering all rows in a dataset, like k-anonymization or localized differential privacy, is useful only in isolation since it may yield results that are susceptible to deanonymization attacks.
- For true data privacy, only a holistic approach across all users and datasets is able to guard against malicious adversaries.
The last takeaway is especially important and forces Chief Information Security Officers (CISO), CIO, CSO, and CDO to consider new solutions.
With our modern frameworks of heterogeneous infrastructure (on-premise and the cloud) and polyglot persistence (many different storage systems), there are many angles of attack for someone who is determined to get hold of sensitive data. The old adage of battening down the hatches, in the realm of information technology, translates into locking down data access – and that is the opposite of being data-centric.
Make access to data a first-class citizen of your IT strategy, or forfeit progress that could be made through modern data analytics. Your call.
And if you’d like to learn more about the benefits of Okera’s secure data access platform, contact us for more information!