
Policies are the statements of intent implemented by a set of rules and applied on a data set. The detailed data security rules, sometimes called safeguards, help to define in the most granular detail and are usually applied to each data element inside a data set (e.g. which department or which role can access sensitive information).
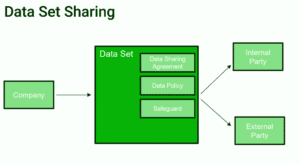
Data governance and data access work as a single smooth process in which data consumers combine Data Elements together (creation of a Data Set) and ask for the data source access without exposing the company to any data related risks.
Benefits and Conclusion
In addition to automation for data provisioning process, there are other huge benefits which companies gain by implementing the “Data Shopping Experience” process using Collibra and Okera, including:
- Minimizing storage capacity and data delivery time
- Reducing data exposure risks
- Reduction in time spent for data access provisioning
- Administration cost-savings
- Centralizing data access

For more information, please check out the 5-minute demo of a Data Shopping Experience in action.
If you’d like to learn more about enabling a “shopping for data” experience that will have your analysts finding and accessing new data within minutes, schedule your consultation with an Okera expert.


