Thoughts about AWS Lake Formation
At AWS re:Invent 2018 conference, we talked to more than 1,000 folks who were interested in what Okera is offering. We’ve had many conversations with great feedback from practitioners that made being at these conferences more than worthwhile. Overall, to me, two questions from attendees stuck out the most:
- What is a Data Lake?
- How do you compare to AWS Lake Formation?
The latter was announced while we were at the conference, and is a meta-service that enables users to tie together existing AWS services to form a data lake and load it with data.
Our short answer to both questions? We love both! Let’s look at this step-by-step, as data lakes are introduced to an organization.
Step 1: Create a Data Lake
It became obvious that the topic of data lakes was separating visitors to our booth into three groups, which reflect the stage of their journey to a fully operational data lake:
- Group 1: Those who have no idea what it is (yet).
- Group 2: Those who are just starting on their journey to establish a data lake.
- Group 3: Those who have a data lake and want to simplify access to the data it contains.
AWS Lake Formation is for the first two groups above, as it can simplify setting up and populate a data lake that is based on S3. It consist of AWS Glue as its technical metadata catalog and ingest/ETL pipeline management. It then uses infrastructure services such as AWS IAM to manage access, or AWS Athena to query the data.
At Okera we have decades of combined experience setting up data lakes using Hadoop, and we know how non-trivial this is when you move to the cloud and try to set up your new data lake. With Lake Formation you will have it much easier, as it manages the resources for you. It also comes with pre-built data processing pipelines that allows you to load data from raw sources in S3 or AWS RDS instances and transform them into partitioned data lake datasets. This latter point addresses one of the most common problems we’ve seen – the difficulty of selecting file formats and how to partition data. Having this tricky process automated (to some degree) is great news!
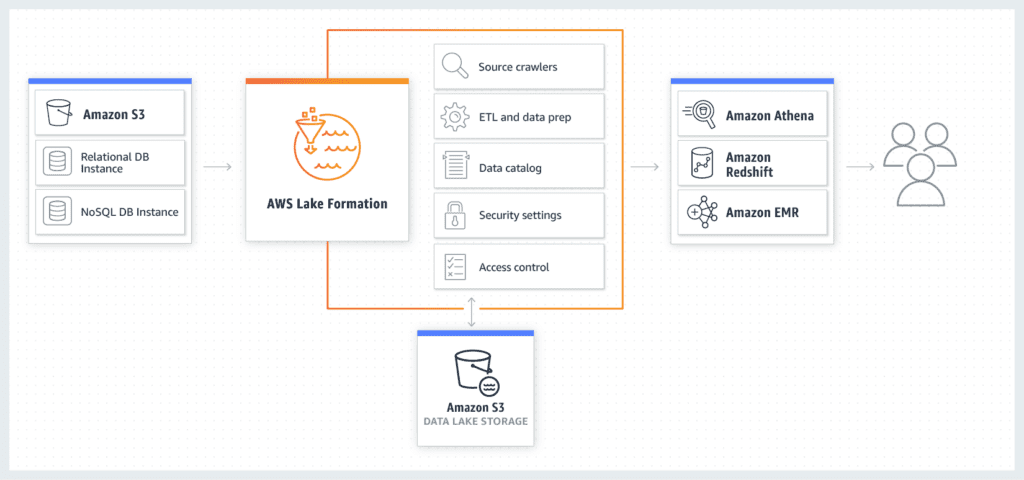
Source: https://aws.amazon.com/lake-formation/
For AWS users, Lake Formation will help new folks such as those in group #1 who are asking “What is a data lake?”, and those in group #2, by guiding them through the process of setting up and hydrate a data lake.
But what about the users of group #3? How does Lake Formation help the advanced users to simplify data access?
Step 2: Democratize Data Access
This leads us to where Okera comes in, that is, liberating data access. Sure, AWS has IAM, S3, and Glue policies that can cover access to data on a per-table basis. The AWS Lake Formation web pages also mention column-level permissions, but not how this is achieved since the current AWS policies only cover table-level ARNs (that is, AWS Resource Names). In general, all policies in AWS are defined in JSON, such as:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:CreateTable"
],
"Principal": {"AWS": [
"arn:aws:iam::account-A-id:user/dev",
"arn:aws:iam::account-B-id:root"
]},
"Resource": [
"arn:aws:glue:us-east-1:account-A-id:table/db1/*",
"arn:aws:glue:us-east-1:account-A-id:database/db1",
"arn:aws:glue:us-east-1:account-A-id:catalog"
]
}
]
}
Supposedly AWS Lake Formation will have a UI that makes managing those somewhat easier, but it still requires a certain level of expertise. On top of that, using table- or column-level permissions is not enough in practice. In fact, we had this for over half a decade with Apache Ranger or Sentry in the Hadoop space. For example, when using Apache Spark on files in HDFS, you could only enforce file-level permissions, which translated into per-table permissions. On the AWS side this is the same as setting a bucket-level permission on S3, which only makes sense to enable binary access – that is, all or nothing – on the table level.
Okera instead took the only viable approach by placing itself between the data and data consumers: We read your data and apply schema, so that we can enforce access control policies at the column-level. Our catalog services also enable hierarchical delegation of permissions much more akin to a database, that is, in form of DDL statements in SQL sent to our servers. This opens the door to many more users who can manage Schema Registry objects such as database, datasets, or functions. For example, see this simple SQL command:
GRANT ALL ON DATABASE salesdb TO ROLE sales_admins WITH GRANT OPTION;
This SQL gives users that are assigned the “sales admin” role full permissions to all tables that are contained in the “sales” database. Since they have been given grant permissions as well, they can delegate permissions to other users as they see fit – in a true self-service manner. All of their actions are protocolled in the central Okera Audit Engine which allows secure, governed, self-service access control management.
While this is great, and to a degree on-par with other governance solutions, it is still a very static way of enabling access: You grant access to a resource and after that the permissions are enforced as given. But that does not give you any more flexibility, and it also means you have to express permissions as a matrix, which unnecessarily increases complexity because now you have to map every user and group into all possible role combinations to manage permissions. What is needed is a more dynamic way of expressing access control.
Step 3: Enable Dynamic Access Policies
In practice, managing data access at scale is non-trivial and error-prone. When it comes to more complex use-cases, such as varying access based on authenticated users, or global filtering of user data for GDPR you will need more than simple access control. For business agility, you want to avoid falling prey to the decade old approach of staging data in different variations as many times as there are user groups. This will slow innovation down and eventually will no longer be practical or manageable.
The Okera Policy Engine does not simply provide access or no access at all, but rather allows you to enforce dynamic filtering and obfuscation of data depending on who is executing a query – all at runtime with no impact on performance. Okera provides powerful functions that can be used to return different values and entire rows based on either the roles of the user; or the permissions of the user to related catalog objects. For example, we enable checks that modify access to a specific column based on access permissions of another column in a reference table. This allows you to express policies that say: If the user has read access to the unmodified values of the birthday column of all customers from the users geographic region, then also allow access to birthday column in all tables that show the same – without having to grant this separately.
Dynamic policy evaluation and hierarchical delegation of permissions are just two of the many features Okera enables above basic access control. With Okera, you can easily, securely, and reliably liberate your data. You can solve problems that the normal data lake cannot solve, and you can do so across not just S3, but also many other file systems, database systems, or cloud offerings. We really love that AWS is helping setting up more lakes with Lake Formation. Now talk to us at info@okera.com about how to solve the remaining problems to truly enable self-service analytics.