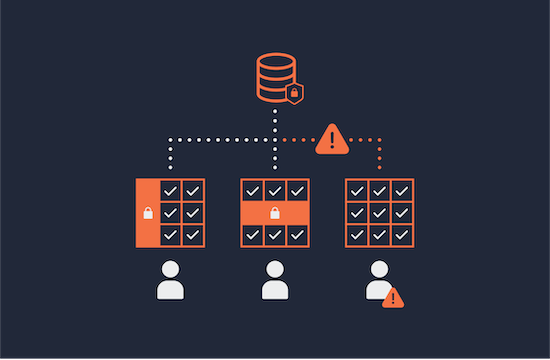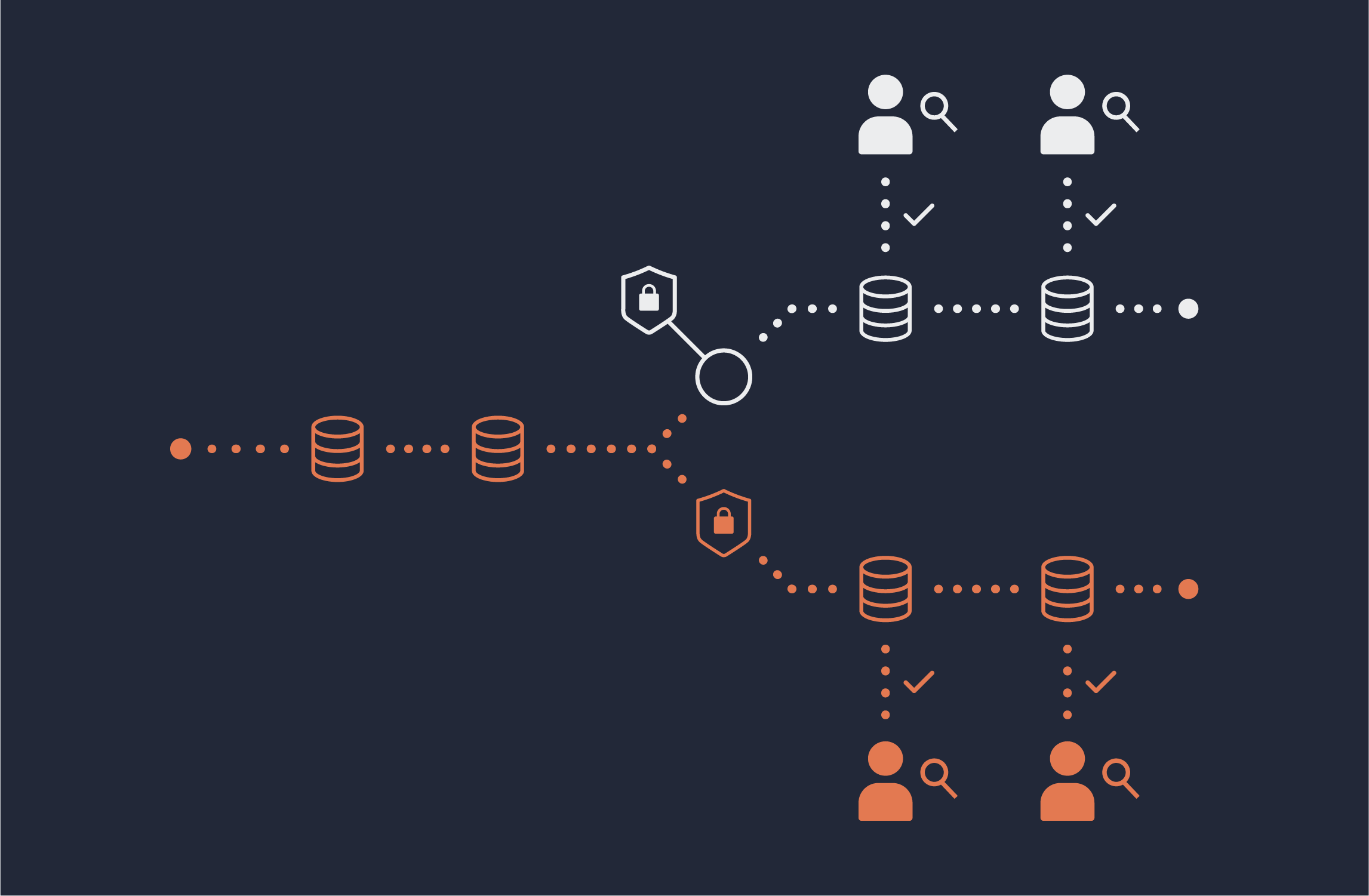
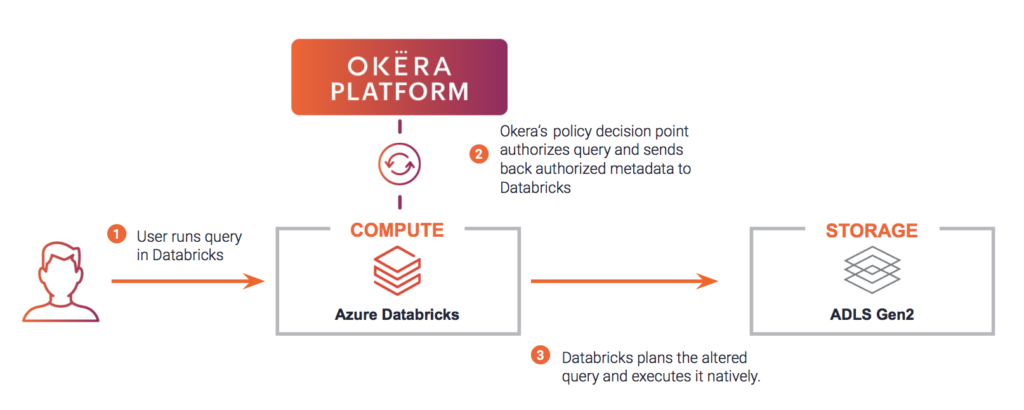
Okera’s platform can successfully implement fine grained access control for Azure Databricks and the full tutorial below will show you how.
As one of Okera’s solutions engineers, I spend most of my time helping our customers and prospects implement the Okera secure data access platform, and I’ve spent many years in the Big Data space trying to secure data at all levels. Today, I’d like to show you how to use Okera for dynamic row-, column-, and cell-level security tightly coupled with Databricks Spark on Microsoft Azure.
Fine-grained access control (FGAC) has been especially difficult with the proliferation of object storage. Okera’s granular security is accomplished using Attribute-Based Access Control (ABAC), which dramatically simplifies the number of policies required to protect sensitive data. Data access control policies can be created and managed using tags, which, when applied automatically when data is registered in Okera, creates an effectively automated policy management.
This tutorial will show you how to implement dynamic FGAC for Azure Databricks using Okera.
Registering a Sample Sensitive Dataset in Azure
We will be exploring a sample dataset called hospital_discharge which contains Protected Health Information (PHI). All names have been randomly generated. We will be implementing several methods for de-identification using built-in functions to comply with the Health Insurance Portability and Accountability Act (HIPAA).
Registering the dataset is easily accomplished using an Okera crawler traversing an Azure Data Lake Storage (ADLS) path. Our sample is a Parquet file, so the crawler can infer the schema and automatically tag sensitive data.
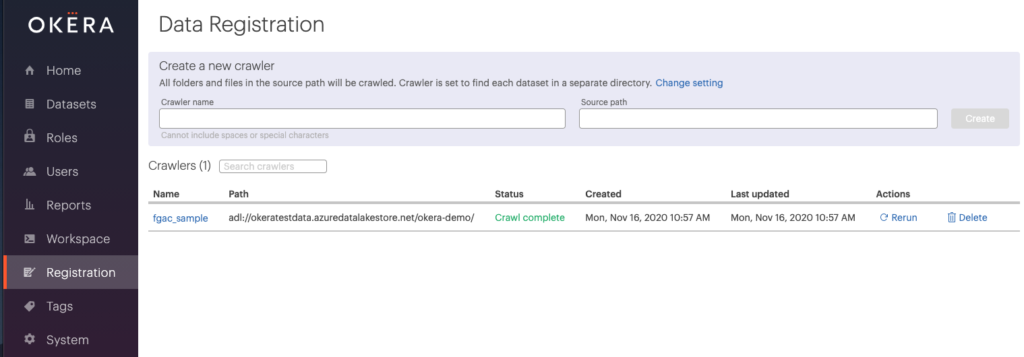
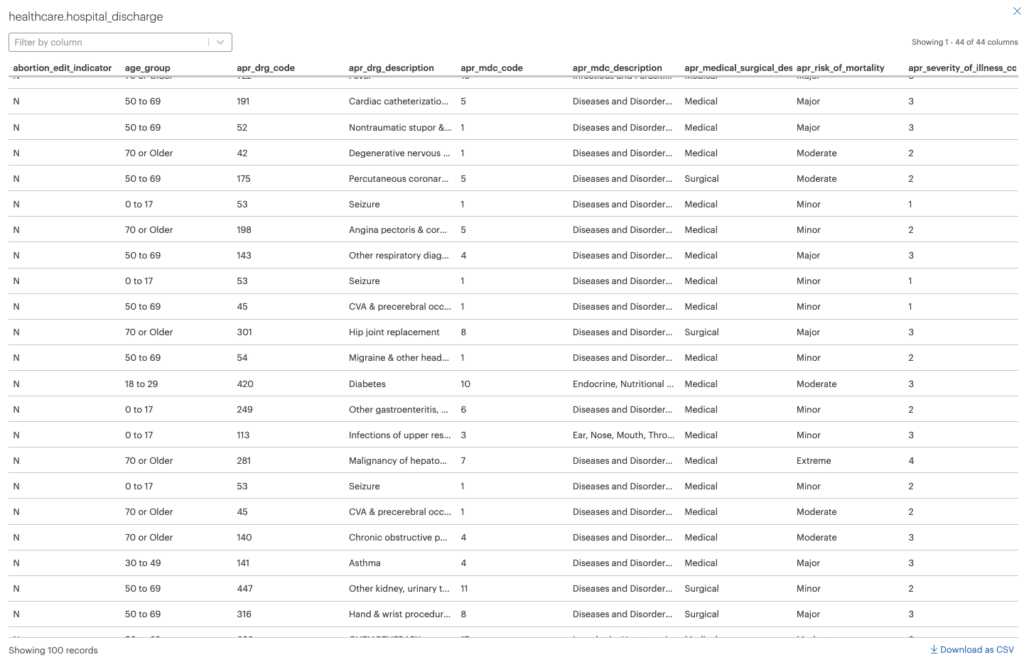
Once the crawl is complete, the hospital_discharge dataset is now registered in the healthcare database. Let’s take a look at the dataset.
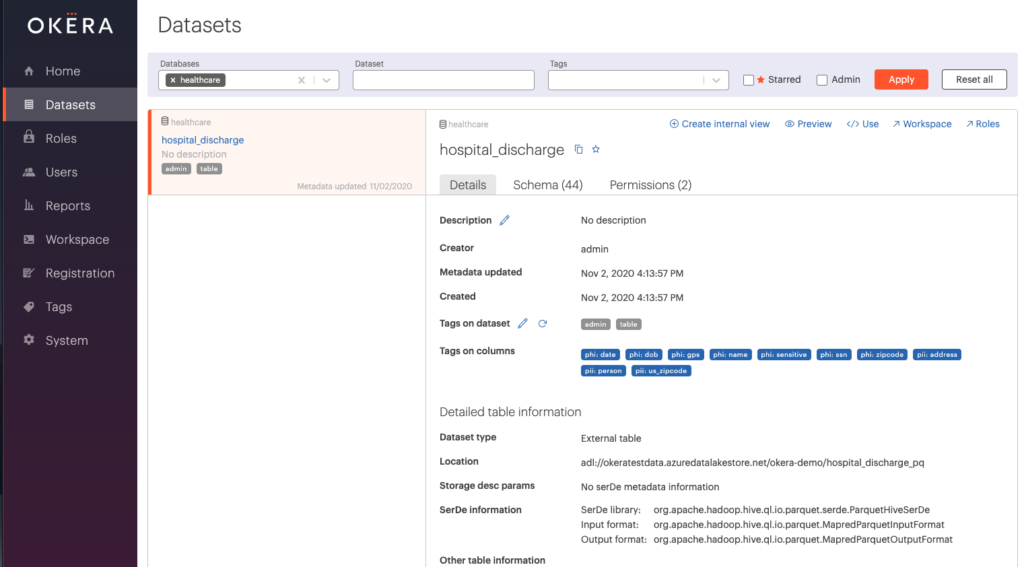
Notice the blue pills next to “Tags on columns.” These are the tags applied using the auto-tag feature. We are currently logged in as an administrator, which allowed us to register this dataset. Now let’s preview the dataset.
Creating a Azure Data Access Control Policy
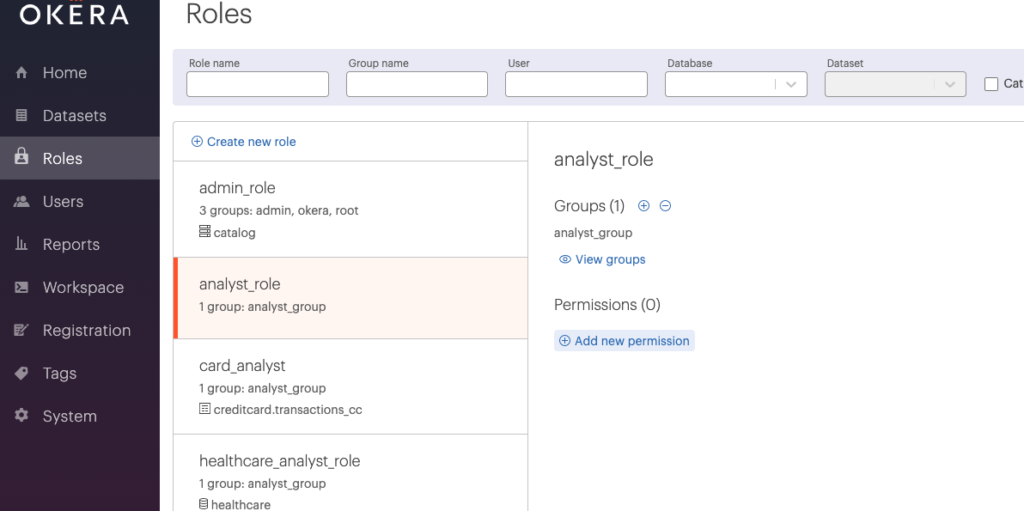
The next step is to define an access policy for our hospital_discharge dataset. We will allow any healthcare data analyst to view our dataset using several de-identification types. Let’s start with our healthcare_analyst_role and “Add new permission”.
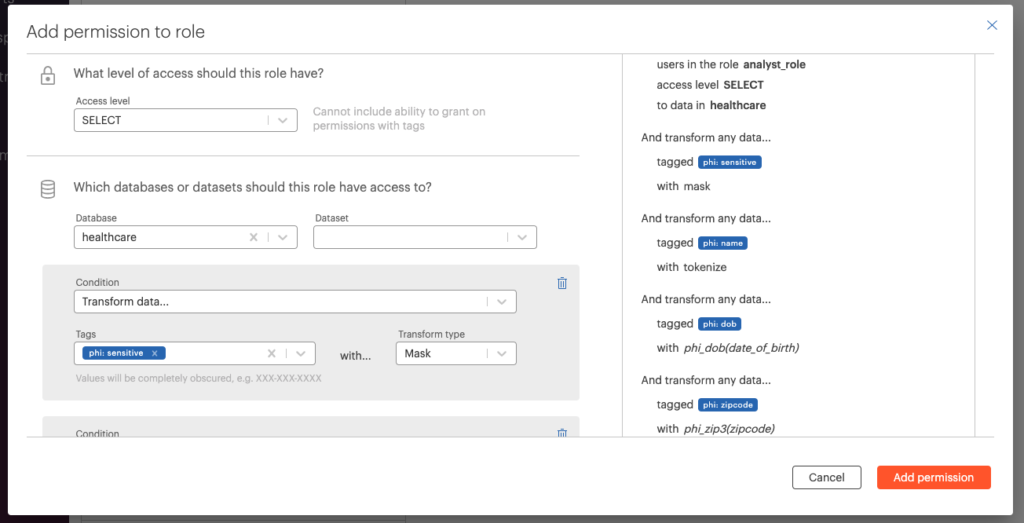
Now let’s build our policy. We’ll use tokenization, masking, and “safe harbor” functions to de-identify our sensitive PHI.
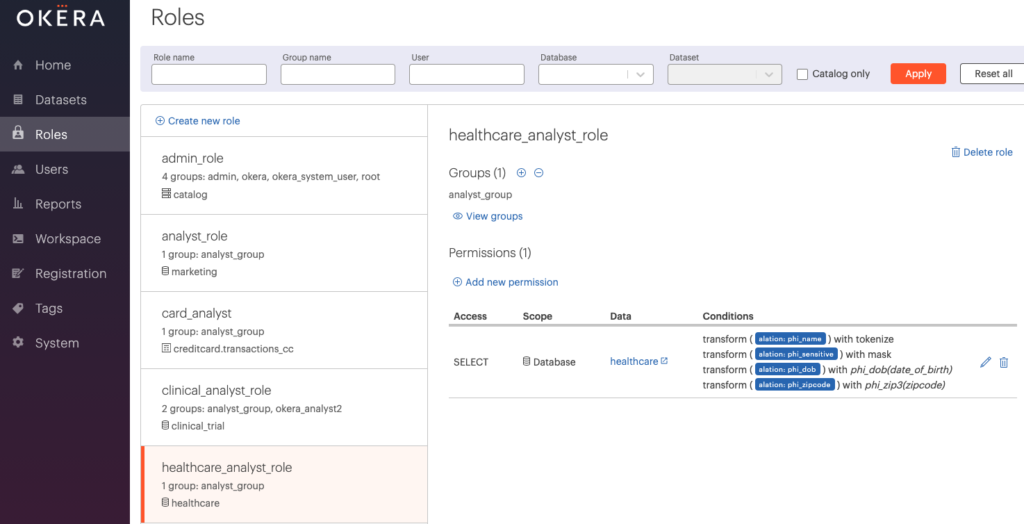
Once saved, your policy page for the healthcare_analyst_role will look like this:
Controlling Accessing to De-identified Data in Azure Databricks
We have already provisioned an Azure Databricks cluster integrated with Okera. The Okera integration with Databricks follows our native big data enforcement pattern for highly scalable performance.
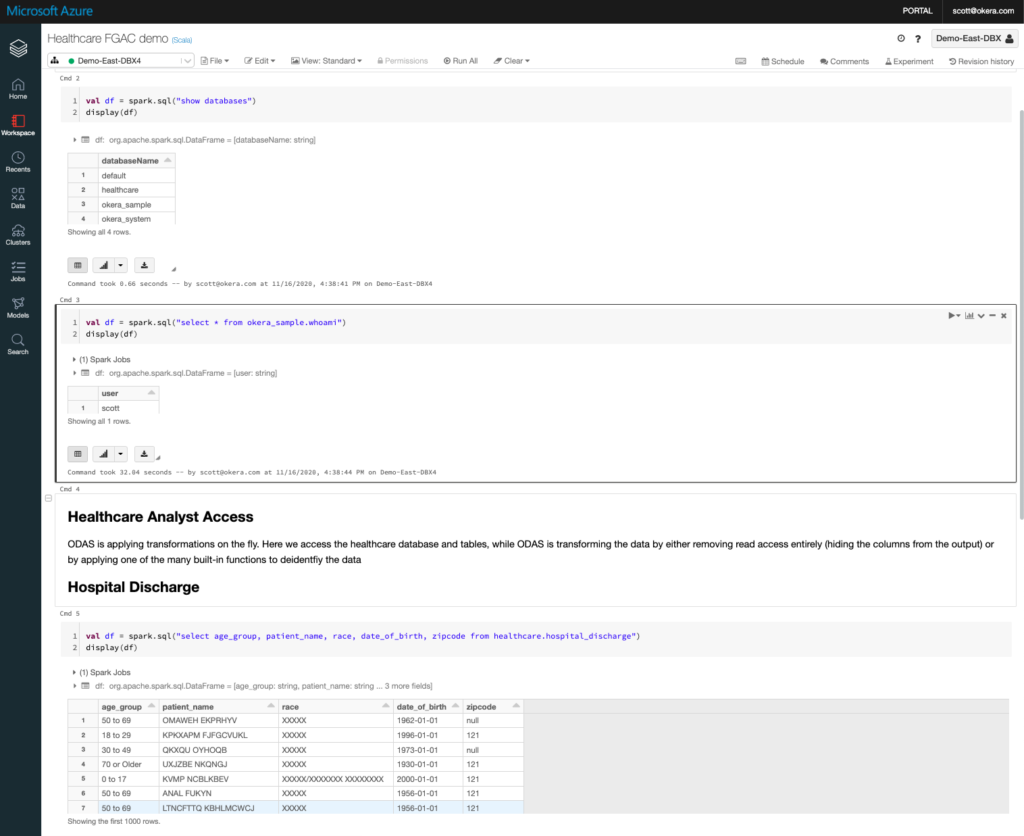
I built a simple Scala notebook to access our healthcare data. I logged into Azure Databricks using Azure Active Directory as “scott’, a member of the healthcare_analyst_role. A quick review of the code:
- Show databases to which the logged-in user has access.
- Show the user Okera is “running as” using an okera function “whoami”.
- Select various columns from the healthcare.hospital_discharge dataset.
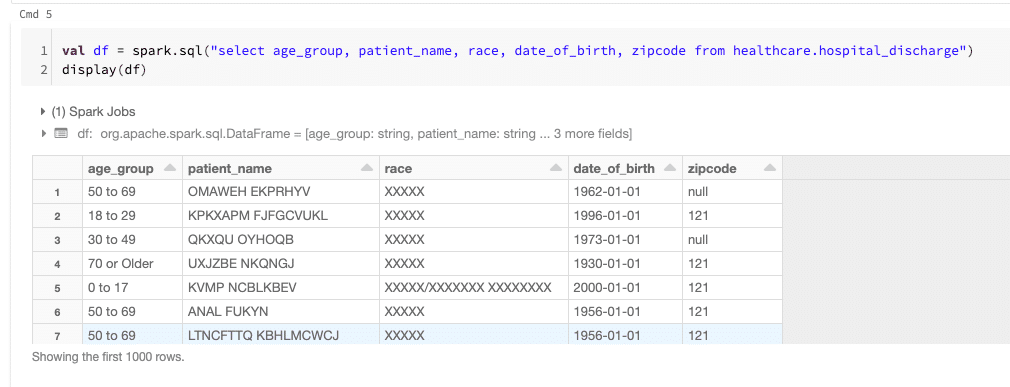
If you look at the results of our query, you will see the de-identification being applied dynamically as per our policy. Specifically:
- Patient_name is tokenized
- Race is masked
- Date_of_birth only shows year of birth (all others are 01-01)
- Zipcode shows only the first 3 digits and if included in the HIPAA list of exclusions only shows 000\
Monitoring Sensitive Data Access with Audit Logs
Each query executed in Azure Databricks against an Okera data source is audited. The audit log shows that “scott” has executed 5 queries in the last twenty-four hours.
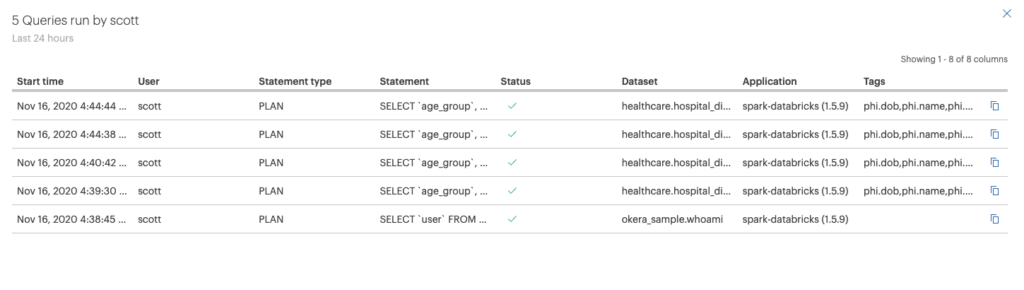
Notice that the application and relevant tags are shown in the audit log. Logs are exposed as system tables so you can build your own reports, like perhaps to look for “toxic combinations” of sensitive tags.
Okera Makes Azure Databricks FGAC Easy
In addition to data masking, tokenization, row- and column-level security, Okera automates a number of other advanced de-identification policies to comply with the regulatory needs of any organization. More information about our supported policy types can be found in our documentation.
If you have any questions about fine grained access control and Databricks, or would like to see a live demo of our platform, please contact us for more information.