Last week at AWS re:Invent, I heard several customers talk about how they are building data platforms in the cloud. There were some clear trends and considerations that several people brought up. As a baseline, businesses are leveraging data and analytics to stay competitive and deliver better experiences for their customers. They want to adopt modern, advanced analytics capabilities and make it frictionless (self-service) for the data analysts and scientists. This modernization of data infrastructure has to be done without compromising on enterprise requirements.
Let’s look a little deeper into what a modern data platform is.
From Traditional to Modern
Companies have been using enterprise data warehouses and relational databases for decades which have served them well. While important, they aren’t sufficient any more. A modern data platform needs to be able to handle new requirements of scale, more workloads, flexibility of tools–and all of that faster than ever before, without increasing the cost or risk to the business.
A modern data platform is not a single technology. It’s a way of building a comprehensive data platform that may use several different technologies that are best of breed at what they do but having them all work in unison to serve the business user.
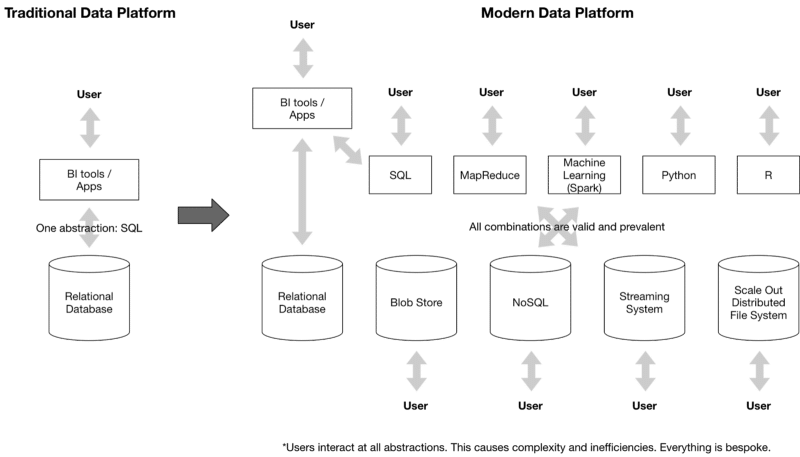
A modern data platform is all about flexibility across all layers. This includes:
- Storage and Streaming: Ability to ingest and store and preserve original data as well as derived and analyzed data assets in systems that are most appropriate for the given workload and data type. For example, some workloads may be suited for blob stores in AWS S3 and others might be better suited for streaming systems like Kafka. A modern data platform should work with multiple kinds of external storage system and not assume all data to be moved into a single system.
- Flexible Analytics: Users can use any kind of analytics tool that they want for the workload they are trying to do. The tools they pick should not be limited to or influenced by where and how the data is stored.
- Hybrid Cloud: A modern data platform should be able to run and support workloads in the data center as well as in the cloud. It should be able to scale elastically and work with ephemeral (short lived and transitory) workloads on-demand.
This presents a major data management challenge for the enterprise due to all the various technologies and patterns involved.
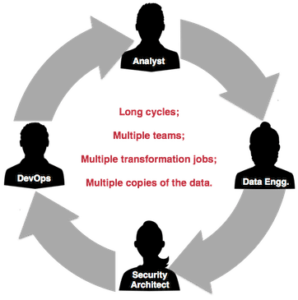 Over the last few years, data management has ended up being the job of the data engineering teams that spend long cycles doing bespoke, undifferentiated plumbing work for every workload. They need to do this to provide their users data in a usable fashion. They don’t get to focus on higher value tasks such as on-boarding new data assets, enabling and optimizing advanced workloads such as machine learning.
Over the last few years, data management has ended up being the job of the data engineering teams that spend long cycles doing bespoke, undifferentiated plumbing work for every workload. They need to do this to provide their users data in a usable fashion. They don’t get to focus on higher value tasks such as on-boarding new data assets, enabling and optimizing advanced workloads such as machine learning.
For an enterprise to build a modern data platform, these data management and engineering efforts are critical. Let’s look into this further.
What is Data Management?
About Okera
Data management consists of the following:
- Metadata Management: Ability to define technical, operational and business metadata for data stored in different kinds of systems.
- Lifecycle Management: Ability to define data lifecycle rules and configurations without having to write complex processing and data movement programs.
- Performance Management: Ability to define the desired performance characteristics regardless of the storage or streaming system, without having to create different version of the data for different performance requirements. This also entails managing file formats, compression, partitioning and caching behind the scenes.
- User Management: Ability to work with the user and identity management system that the enterprise is using, such as AD, LDAP, Okta etc.
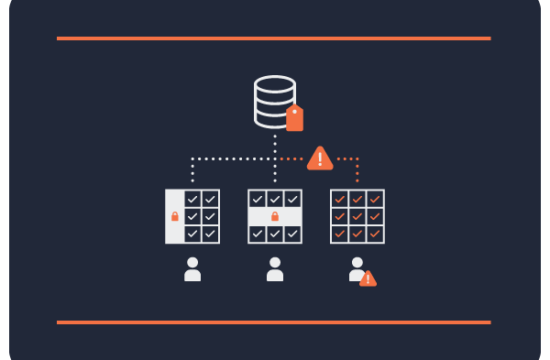
- Security: Ability to define rich, fine-grained access control rules that are not only limited to the roles and groups to which users belong but also a function of the metadata like tags.
- Data Quality: Ability to define and understand data quality characteristics for data coming from different sources.
- Governance: This entails auditing access and tracking lineage of data assets as they are created.
All of these are required to enable the consumer of the data, the data analyst or scientist, to get access to data so they can do their analytics. In essence, these are the foundations for a modern, self-service data platform.
Data Management for the Modern Data Platform
Relational databases have data management functionality and there’s rich tooling available around them to augment their functionality. The modern data platforms that we are trying to build go beyond relational systems and include technologies with different kinds of abstractions and maturity. To enable an enterprise-grade modern data platform that provides data analysts with the ability to get access to data in an easily consumable manner, we need the data management functionality available outside of any of the storage or analytics platforms. That’s how you get the flexibility on both those layers, thereby making the modern data platform a reality for the enterprise and the mainstream analyst.
The goal is to decouple the task of staging data, and consuming it. We used to see the complex chain described above, in which a project team is responsible to establish the entire data processing pipeline, including ingest, ETL jobs, processing and delivery of the final product. This is turned upside down in a modern, self-service data platform, which provides the data and tooling to build micro pipelines. They differ in that a single person, the analyst or scientist, is set up to write any necessary processing to deliver the final product. This cuts project times into fractions of what used to be common: instead of 6 to 12 months, we see turnaround times of mere days or weeks.
Summary
Enabling users to establish their own data pipelines with a tool of their choice is a powerful feature. Hiding the nature of the underlying data source simplifies the processing functionality, and allows to merge data from many distinct storage types, including file and object stores, as well as stream systems. It’s obvious that there are many technical challenges that need to be solved when introducing the modern, self-service data platform into an organization. With a suitable architecture and approach, it is possible to solve these so you can start to reap the benefits of all the cutting edge data processing and analytics technology that has been built over the last decade.