In recent years, we have witnessed a massive transformation in the kinds of technologies available to companies to work with large amounts of data. However, this transformation has not been smooth sailing. People have run into numerous challenges on the path to adopting big data, ranging from a lack of metadata management to a lack of security and governance controls. All of which impede a company’s ability to derive value from their investments. More importantly, these challenges fundamentally impact the productivity of people working with these new technologies. Data professionals spend the majority of their time in plumbing, building custom integration, and creating copies of data for every single use case and every single user. This is a massive drain on productivity and a massive waste of resources.
In almost a decade of helping customers adopt new data platforms, I have witnessed this struggle first hand. The day to day struggles of data professionals and platform teams (i.e., data engineers, consumers, owners and stewards) bothered me. I felt we as an industry have missed the mark.
My co-founder, Nong, and I spent numerous hours talking about this problem space, what it could look like and where the gaps are. Not only did we share a common vision for how to solve the technological gap, we shared a common philosophy for the kind of company we wanted to build, the kind of products we would like to offer, and how we would like to serve our customers. That alignment quickly became the genesis of Okera (called Cerebro Data at the time).
We started our company in April 2016 with the intent of solving data management problems for customers in a data-centric way; a way that was infrastructure, platform, and tool agnostic. It would be a product you could run anywhere (cloud / on-premise), use on any data platform, and with any analytics engine; a product that didn’t need you to do a lot of custom engineering or create copies of data. This was a lofty goal and many scoffed at us, but we believed we were on to something even if we weren’t able to articulate it crisply at the time.
We looked to learn not only from our own experiences but from historical research on data platforms and databases. During that time, I re-read E F Codd’s original paper on the relational model that formed the basis of the relational database, a technology that has served us very well for decades and continues to do so. The first line in that paper says “Future users of large data banks must be protected from having to know how the data is organized in the machine (the internal representation)…”
That was our “aha” moment. We knew there was something there and this has become the foundation of what we are building.
In the world of data management, the first challenge we are addressing is the tradeoff between agility and governance, between access and security. Our mission is to make data more accessible and better governed for our customers. We give them the ability to harness the new data platform technologies without compromising on enterprise requirements. We’ve been executing against this mission for the last two years with a few core tenets – delight our customers, add massive value, and have a ton of fun along the way.
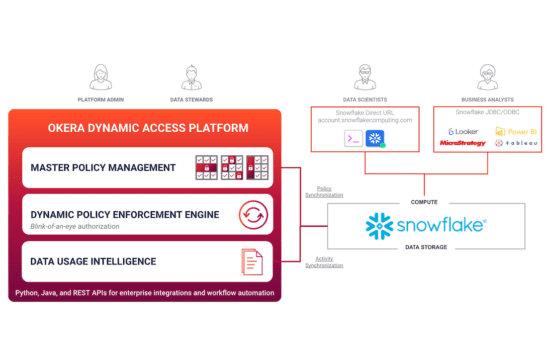
This brings me to today – a day that every founder anxiously awaits. Today, I’m honored to announce a big milestone in our journey: Our first product, the Okera Active Data Access Platform, is now generally available. We have also raised $12M in Series A funding, and have multiple customers who are in production with our product. Okera is open for business and we are so excited to be here.
This is an important milestone in building Okera – a company that’s focused on solving some really hard challenges in the world of data. I’m grateful to our early release customers who have worked shoulder-to-shoulder with us on implementing this product vision. I’m grateful to our team for their perseverance, dedication and passion in bringing this product to market. We are not just about solving challenging problems, but also building a company we are proud of. For us, that means building something that solves a real problem for people and makes their lives easier and more productive.
I’d like to close this note out by saying – This is Day One for us at Okera very much Day One for data management with this new approach. We know data professionals are continually looking for ideas and advances in the field, and we intend to share what we learn along the way. If you want to stay connected and join us on this adventure, subscribe to our newsletter on the right or drop me a note here.