In 2003 and 2004, Google – arguably the largest data-driven company at that time – released the seminal papers on what would become the foundation for Hadoop and the idea of a data lake in general. A scalable storage service that could affordably hold any and all data, it would serve as the basis for a slew of use-case-specific compute engines, from the venerable MapReduce to the more flexible Spark (or may I dare mention Microsoft Dryad here?).
When those papers were published, Google was already in production with that technology, putting the actual time of development at around 1999 or 2000. The most interesting part though is that in 2020, we are still struggling to build data lakes that are both universally useful and usable at scale.
This brings us to the various dimensions of scalability for data lakes, which include:
Physical Scalability
This problem can be considered solved. You can buy bare-metal hardware or subscribe to cloud services to build scalable data lake infrastructure. Cost may impose certain restrictions on what you choose, but with enough revenue, you can justify the right architecture for your needs. Hardware, whether real or virtual, is commoditized enough to make this exercise a viable option.
Data Collection Scalability
One of the main contributing factors as to why we are still living in the age of petabyte-sized lakes, as opposed to exabyte-sized or beyond, is that most companies still struggle to acquire and/or collect all the data they could possibly need. But, as with the above point, this is not due to a lack of ingest technologies. Rather, enterprises are still trying to figure out what “collecting more data” actually means to them.
Data Processing Scalability
This leads to the processing of data, commonly referred to as compute. Again, there are many choices, like the aforementioned Spark, or plain Python with Pandas and Jupyter notebooks. Even SQL is strong here, with many compute frameworks offering it as a segway into the pure imperative approach of these frameworks for traditional, declarative developers and DBAs. Scalability is a function of the framework, and ranges all the way from excellent (Spark) to rather poor (R).
Data Governance Scalability
Once the data is the lake, it needs to be curated and made available to data processing frameworks. This is where the map reads “Here be dragons”; after half a century of data processing, the data governance field is still oddly shaped and ill-defined. Thanks to the increase in complexity from the advent of the data lake, new data formats, and the n-th degree of freedom in how to process them, it is now a greater mess than ever.
I thereby postulate that the biggest challenge involved in scaling a data lake is data governance. But why is that?
Scaling Data Governance
You may already know about or have experienced the trouble with maintaining data in regular data warehouses and databases in general. In a data lake, this problem is exacerbated many times over. How can you avoid the pitfalls, both old and new?
Assuming that data quality, lineage, maintenance, etc can be solved by acquiring the right tools and automating the right workflows, the remaining challenges to scaling out a data lake are as follows:
Knowing what data you have
Here, I am not only referring to data discovery in the business sense, where you would employ a data catalog solution such as Collibra or Alation. This knowledge is about the raw data itself, and how that affects data access policies. Data stewards must analyze datasets using mechanisms like tagging to highlight personally identifiable information (PII) or other sensitive data.
Machine learning technologies, trained to identify common patterns such as credit card or social security numbers, can strongly support the data stewards in their work to tag datasets and columns alike. Only then you can onboard the deluge of data floating into an organization every day.
Easily defining data access policies
Once the data is tagged, you need to be able to define access policies that apply to large amounts of users implicitly and provide access to a vast amount of datasets without needing special exceptions. Administrators responsible for granting access to data are in desperate need of easy-to-use tools to support them here.
At scale, it’s impossible to manage multiple permission systems that follow divergent ideologies. This becomes obvious when you mix POSIX-like file systems with database system permissions, as their granularity differs tremendously from each other. One sees a dataset as a directory with many binary files in it, while the other is looking at row- or column-level filtering and masking.
Enforcing the policies across all tools
Once the policies are defined, you need to ensure they are enforced wherever users access data. This only works if all access points are protected, including all data sources that users potentially want to access. It’s not enough just to protect the file-based access APIs when an engine reading the same data with broad permissions is providing access to the data anyway.
In effect, you need to control the flow of data at every level and for all APIs that users want. Users can then bring their own compute frameworks and connect them at the level of their choice, not where the missing policy enforcement is making them.
Enabling on-demand audits
Simplifying the process of security checks helps not only in the case of a regulatory investigation, but also to determine the use of data. How good is it when auditors or managers need to consolidate disparate log files in order to learn who is using what data and how?
A single audit log with homogenous entry records will easily import to a SIEM tool, but can also drive reporting for LOB managers to efficiently manage their data, and understand what data is being used regularly and what is not.
This brings us to the last part of scaling data governance for data lakes.
If you think back to how applications were developed in the 90s and early 2000s, you see a pattern that was invented to decouple centralized IT departments from the LOBs. Managed database systems (MySQL, PostgreSQL, Oracle, DB2, etc) provided a service wherein developers were given reign over their own data. A database administrator would create a database and permit developers to create any dataset that they wanted to use. Each application and group of developers had their own database, and the LOB would implement the business logic.
Then came the data lake, forcing everyone to deal with a scalable file system and its semantics, while also adding compute engines that needed coarse-grained access to the LOBs’ data files. Initially, the solution was to set up a data lake for every LOB, which solved the permissions issue. But as time went on, the number of compute engines grew, and the need to centralize the management of these clusters – ideally consolidating them into one – came into being, the permissions process got stuck in limbo.
We need to go back to this proven principle: manage infrastructure centrally while delegating the management of data – that is, data governance – back to the LOBs. The important data management personas, like data stewards and data administrators, are located in the LOB and have been given reign over their part of the lake. They require simple, machine-supported tools to tag their own data, define permissions for it, and allow users to access what is needed. A single audit log of the central, shared data platform will then filter relevant events to drive the necessary reporting.
The following diagram shows how we at Okera see this process (which we like to call distributed stewardship), starting at deployment and going all the way to when the users are consuming data.
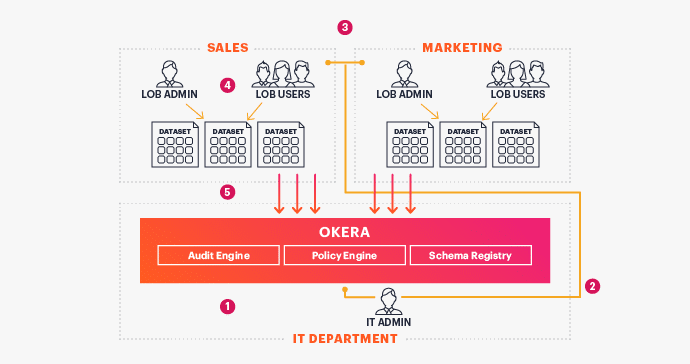
- Central IT installs and manages Okera for operations
- Central IT bootstraps LOB by setting up the LOB Admin
- LOB Admin onboards LOB datasets and defines access policies
- LOB users access data securely
- Client applications use Okera cluster for data access
Note that once steps 1 and 2 are complete, the LOBs can manage everything else on their own (steps 3-5). It doesn’t matter how many LOBs there are in total; each one is autonomous, but can give other LOBs access to their data as necessary.
TL;DR
Solving for data governance at scale, especially the topic of secure data access, requires a decentralized approach, supported by centralized infrastructure:
- Managing vast amounts of data must be delegated to those who know what is available – the lines of business where the data producers and owners are located.
- The data access layer should help and guide LOB staff to make defining coherent and holistic access policies at scale very simple. This requires data introspection with pattern recognition based on trained machine-learning algorithms to suggest appropriate tagging of sensitive data, which accelerates the adoption of different data sources.
- All possible access points must be protected by the same set of rules. Instead of being forced to write disparate policies at the level and granularity of the source system, the policies should be homogeneous, expressive, and easily defined, and should be enforced automatically (as applicable) by the access control layer.
- Insight into data usage should be easily accessible to data owners and LOB managers, as well as central CxO staff members tasked to analyze the organization as a whole.
Essentially, to solve our data governance problem, we need a return to the simple framework of those early days – where access was bootstrapped by the IT department, but managed by the LOBs – without compromising on the benefits of the modern scale of big data.
If you’d like to know how we at Okera can help take that burden off your shoulders, contact us!