Protecting Big Data Frameworks with Proxy Data Access Architecture
Earlier this year, my esteemed colleagues Nong and Itay published a post titled Securing Data Access on the Modern Enterprise Analytics Platform, which went into detail about some of the problems around access control and the heterogeneous technologies in a modern data lake (think, “bring your own engine”). Multiple technical solutions need to be supported to strike a balance between performance, ease of integration, and the required data security features.
One of these solutions involves the enforcement of access control between the user and the compute tool. This is especially useful for analytical frameworks like the Hadoop stack or software-as-a-service (SaaS) offerings, which often have little to no options for more advanced access control features; changing the system is technically or economically not viable, so you have to use what is already there.
Legacy and SaaS Tools
Consider the following flow diagram depicting a request made from a client application, such as a business intelligence (BI) tool, querying data using either Hive or Impala in a Cloudera Hadoop cluster (CDH):
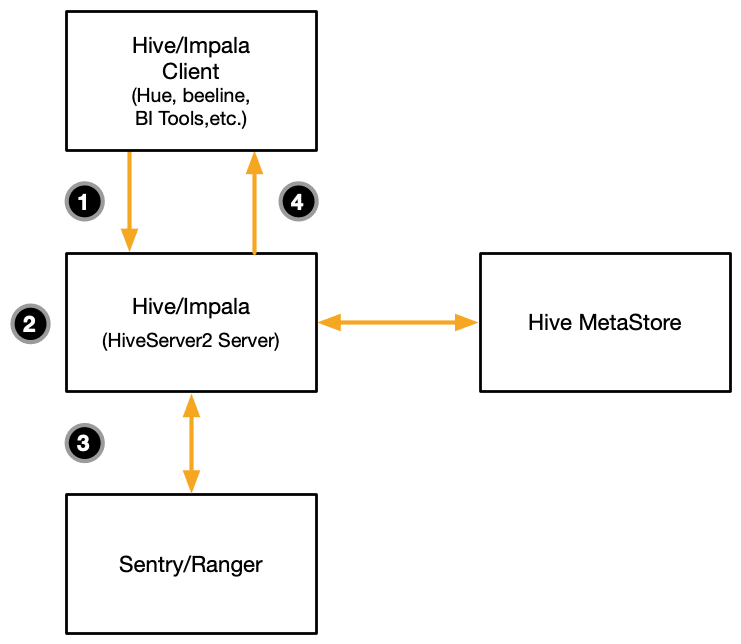
The flow is as such:
- The user issues a request for data using their client application, which is sent as a SQL statement to either a Hive or an Impala cluster.
- A HiveServer2 API compliant endpoint, referred to as the coordinator node, receives the client request and plans its execution across the compute nodes of the cluster. This involves loading the dataset’s metadata from the metastore.
- While planning the query, the coordinator node sends the credentials of the user making the request to the Sentry or Ranger API in an attempt to retrieve any applicable access policies.
- The query is executed and the results streamed back to the client application in batches of rows.
While this looks easy enough, it raises a few questions around access control.
Complexity – In many data lakes, the policies that define what is available or not are implemented in a decentralized manner, as plugins for each service or as push-down actions from a central access management system. For Hadoop, these are usually Apache Sentry or Apache Ranger, which rely on Hive or Impala to enforce the intended level of access. The audit log records are also generated decentralized, and differ in their physical manifestations between each tool. All of this makes managing and auditing access much more difficult — and that’s without even considering trying to standardize access policies across all the other tools, applications, and frameworks in the stack.
Granularity – The heterogeneity of a data lake often forces policies to match what is available, and across engines, this is further reduced to the lowest common denominator. Users are only given coarse-grained access — all or nothing access to files, or potentially only to the columns are readable for structured data. What’s missing is the ability to define policies that are as sophisticated as they are granular. Instead of defining permissions on a per-dataset basis, the better option is attribute-based access control (ABAC) which allows for policy definition that can span datasets and databases while being expressive enough to handle dynamic data transformations for non-privileged users.
Okera’s Solution
Okera’s key value proposition is in unifying data access governance, with a single Metadata Registry, Policy Engine, and a central Audit Engine. For this particular access pattern, we have a solution that is lightweight in terms of interoperability with the existing data lake while guaranteeing the broad applicability that a unified access control layer must provide.
Consider the updated flow diagram that shows Okera using a proxy pattern to inject itself with minimal effort into the request path of an application:
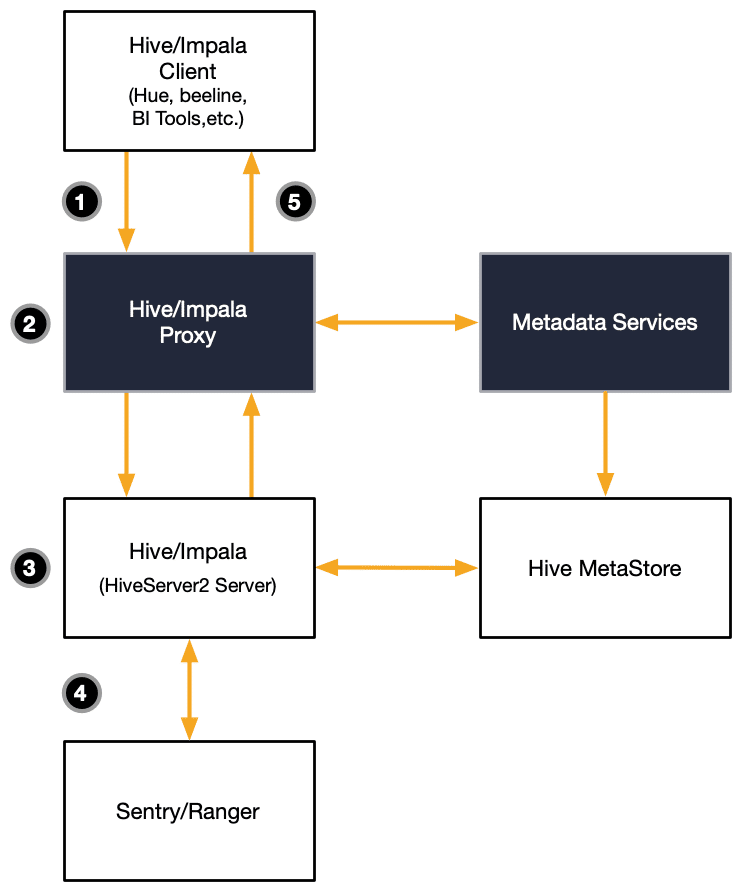
The request flow is modified as such:
- The user and their client application send the request for data, but instead of sending it directly to the compute cluster, the application is reconfigured to send the request to the Okera-provided Hive or Impala proxy instead.
- Our proxy authenticates and authorizes the user, and loads the metadata for the query and applicable access policies. With this information, the proxy rewrites the original query to comply with access policies and then sends on the query to the original Hive or Impala coordinator node.
- The query is planned and scheduled for execution across the cluster nodes as before, but now in the context of the Okera proxy user.
- This means that the IT infrastructure team only has to manage a single set of permissions, while the actual data access permissions are managed by Okera and can be delegated to the lines of business (LOBs).
- Finally, the result is streamed back in batches of rows through the Hive or Impala coordinator node and the Okera proxy to the calling client application. This is a lightweight operation and does not impose a burden on the proxy, even when handling many concurrent requests.
The last point is of particular importance if the organization is looking to migrate access control from on-premises (or compartmentalized off-premises) Hadoop clusters to a more generalized data lake.
Benefits
For many enterprises, combining the larger IT ecosystem with the idiosyncrasies of the Hadoop stack (think Ranger/Sentry or Kerberos) meant they were unable to migrate workloads to more contemporary architectures, like object storage services with separated yet flexible compute engines. With this integration type, where Okera is acting as a proxy, the workload (like a BI application or data pipeline) is migrated once using Okera’s proxy endpoints and then the backing storage can be freely moved around. You could move all or part of the HDFS dataset to the cloud and update the metadata to point to the new location without any interruption to the clients.
More importantly, you also get the benefits of a modern data access platform while retaining the existing data assets without interrupting their current users. If you have an existing CDH installation with many existing users – ad-hoc queries from data analysts, 24/7 traffic from data pipelines crunching numbers – you can migrate workloads to the Okera proxy-enabled solution and reap the benefits of modern data security features. Again, this is without any interruption to existing clients.
As I mentioned at the beginning, this is only one way to introduce Okera into existing applications and frameworks. With the other three integration types, you can cover all possible access patterns and have a single access layer protecting your data no matter what path the clients choose. Okera’s unified policy store and auditing capabilities mean that both legacy and current paths of access are equally guarded and traceable. And with the new ability to distribute permissions to the LOBs, central IT no longer has to manage assets they don’t own.
Over the course of the next several weeks, we will dive deeper into the other options and explain their benefits. Look out for the upcoming blogs to learn more about Okera’s flexibility in providing the most efficient and secure path for users to access data dynamically and seamlessly!