Note: A version of this article was originally posted on DZone. What you are reading now has been enhanced with more details around the suggested solution.
Amazon Web Services Identity and Access Management (IAM) is designed to track system users and information regarding how they get authenticated. It is commonly used to protect objects, such as data files, in Amazon’s Simple Storage Service (S3), which, in turn, forms the most important layer of an S3 Data Lake.
With various levels of security layers and different departments responsible for various types of data, there are a number of intricacies and challenges involved in managing the security and governance of AWS IAM.
This article looks at how AWS IAM works and whether IAM is slowing down data projects, as well as a possible solution.
Security Layers
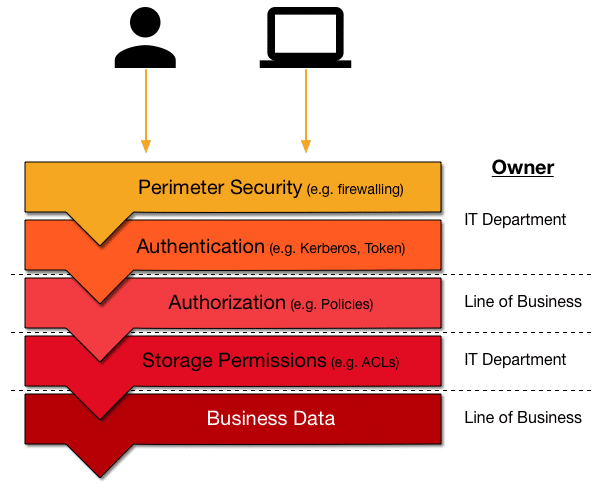
Before we look at the difficulties of managing access to resources in S3, we are going to look at the broader picture of defining a state-of-the-art security architecture. There are more layers than just authentication and authorization, both of which are covered by AWS IAM. You also need, for example, an airtight perimeter control. This leads us to the common security stack shown in the diagram.
Perimeter Security
Usually, the technology for this first layer is network-based and involves tools such as firewalls, virtual networks, and intrusion detection services. Drawing on an airport analogy, this is the TSA agent controlling access when you enter an airport. It is literally the first line of defense.
Authentication
Keeping with the above example, next is the border control agent asking for your passport. For computer systems, the equivalent is authentication, which, like a physical passport, proves that you are who you claim to be. Here you will find services such as Kerberos, or token-based systems such as JWT or OpenID.
Authorization
Once you have been granted access, the services need to know what you are allowed to do, which is part of the authorization process. Typically this is a list of permissions or policies that define your role or business purpose. These are stored in directories or other enterprise-wide information services (for instance, Active Directory or OpenLDAP) and commonly define group memberships. For example, user Jane Doe belongs to the group Marketing US East, which means she needs to be able to access all relevant data to fulfill her duties but may be restricted from looking at the data meant for Sales US West.
Service Access
Next up is the actual storage layer, which comprises the services storing and providing the business data. The storage systems have their own idiosyncrasies and proprietary permission features. This is where you deal with file ACLs or database grants.
These layers certainly make sense and mirror real-world processes nicely. But not as obvious is who owns each of these security levels. It can get messy as business units want to control who has access to what data, while IT departments traditionally are responsible for infrastructure and enterprise-wide services such as the network, the directory, and storage. This is where, in practice, the data lake architecture falls apart and turns into a data swamp if not managed properly.
AWS IAM in a Nutshell
With every account, AWS offers a free service referred to as IAM, short for Identity and Access Management, which provides common entities, such as users, groups and roles, to the account owner. These are used to enable access to other AWS services based on permissions, commonly specified as policies in JSON format. For example, the following policy grants access to a specific collection within the DynamoDB service (source):

These policies can then be attached to the above entities (referred to as identity-based policies), or directly to the resource of a service if supported (referred to as resource-based policies). One common example in the context of an AWS SE data lake is to
- Create AWS IAM roles that have permission to access the S3 service endpoints (defined as a set of actions) and
- define S3 bucket policies to allow or deny access to the contained objects.
The latter is especially needed in shared AWS accounts since by default all IAM entities of an account automatically have access to its resources.
By now, it should be clear that AWS IAM-based security is far from trivial. You have to handle proprietary JSON attributes and lock down or open up access to resources in multiple places, which can lead to mistakes that expose sensitive data.
Requirements of Access Control in Data Lakes
The limitations and challenges of IAM as access control become even more obvious as privacy regulations like GDPR and CCPA demand increasingly more features from data security, like the “right to be forgotten.” Based on conversations with many IAM supporters and detractors, the following requirements should be considered for anyone managing an enterprise data lake.
- IAM Integration – Since IAM bucket policies are single JSON structures containing all access roles for a given bucket, they are very error-prone. There is a need for a better, easy-to-use access control system to manage granular access control. Any new system must integrate with the existing IAM service.
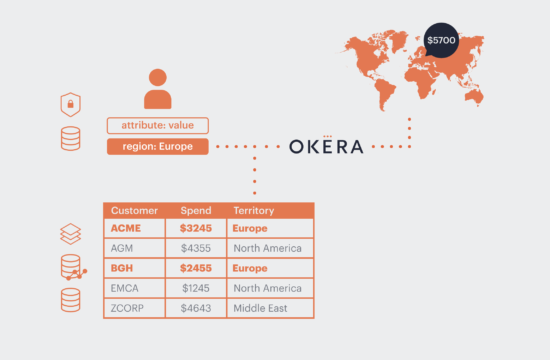
- Distributed Access – The system should let you delegate permissions easily to data owners so that they can control access to their data, removing the need for time-consuming, cross-functional processes.
- Single Unified Layer – Ideally this access control mechanism should act as a single unified security layer, covering not only authentication and authorization but also audit event logging.
- Unified Governance – No access control system is complete without the capability to see who is using what resources in your data lake.
- Privacy Compliance – Global data privacy regulations demand that data be discovered automatically, tagged correctly, and that the right information is always presented to the right people without making numerous copies of the data.
- Sensitive Data Protection – Besides making the right information available to the right roles, sensitive data must also be obfuscated for protection against threats both internal and external.
IAM Slowing Down Data Projects?
If we go back to IAM, and AWS as a whole, the issue is the same: IAM is overloading IT and business interests just like the pre-data lake system architectures did. You need to
- have someone capable to write highly complex JSON policies (which can grow to multiple pages, even exceeding the maximum allowed length of up to 20KB),
- ensure all business units are included as either users, groups or roles that should have access,
- assign the policies to the right entities, and
- verify access is working as expected.
This process spans many IT and business roles, which usually work through a ticket management system such as JIRA or ServiceNow. Again, errors are likely made and the process is cumbersome and slow, hindering innovation and fast iterations on data projects.
Lastly, AWS IAM only has very limited support for fine-grained access control. Only recently AWS Glue did add the ability to filter rows or grant access on a per-column level. This does not include any masking, tokenization or other advanced features, such as differential privacy. Nor does Glue extend to all AWS services yet, let alone non-AWS ones.
Fine-grained Access Control and Okera
The solution is quite simple. Okera offers a single, unified security layer that covers authentication, authorization, and audit event logging. Instead of dealing with technical details across multiple parts of the organization, with Okera you simply
- Set up access to storage systemsone time for the Okera services, and
- Delegate business data administration to the lines of business thatowns the data.
In other words, you define a single, service-level IAM role for Okera and allow it to access the protected S3 assets. You also add the necessary IAM roles for the data producers to store the data in the first place. After that, no further IAM interaction is needed, eliminating the error-prone manipulation of all access rules when only a subset is affected (recall, IAM bucket policies are single JSON structures containing allaccess rules for a given bucket).
Since permissions are delegated to the data owners, controlling access to their data is where it needs to be. No time consuming cross-functional process needed.
This solves the IAM conundrum in an elegant way, matching the existing enterprise organization while removing the requirement for unnecessary change.
Take Away
As your data lake continues to grow with many more types of workloads and users, it is imperative to evaluate other alternatives to IAM that may better suit your needs. With more enterprises looking at hybrid cloud solutions to avoid service-related risks, unifying data governance is even more important. AWS IAM access control may not be the panacea, but Okera offers a compelling alternative.
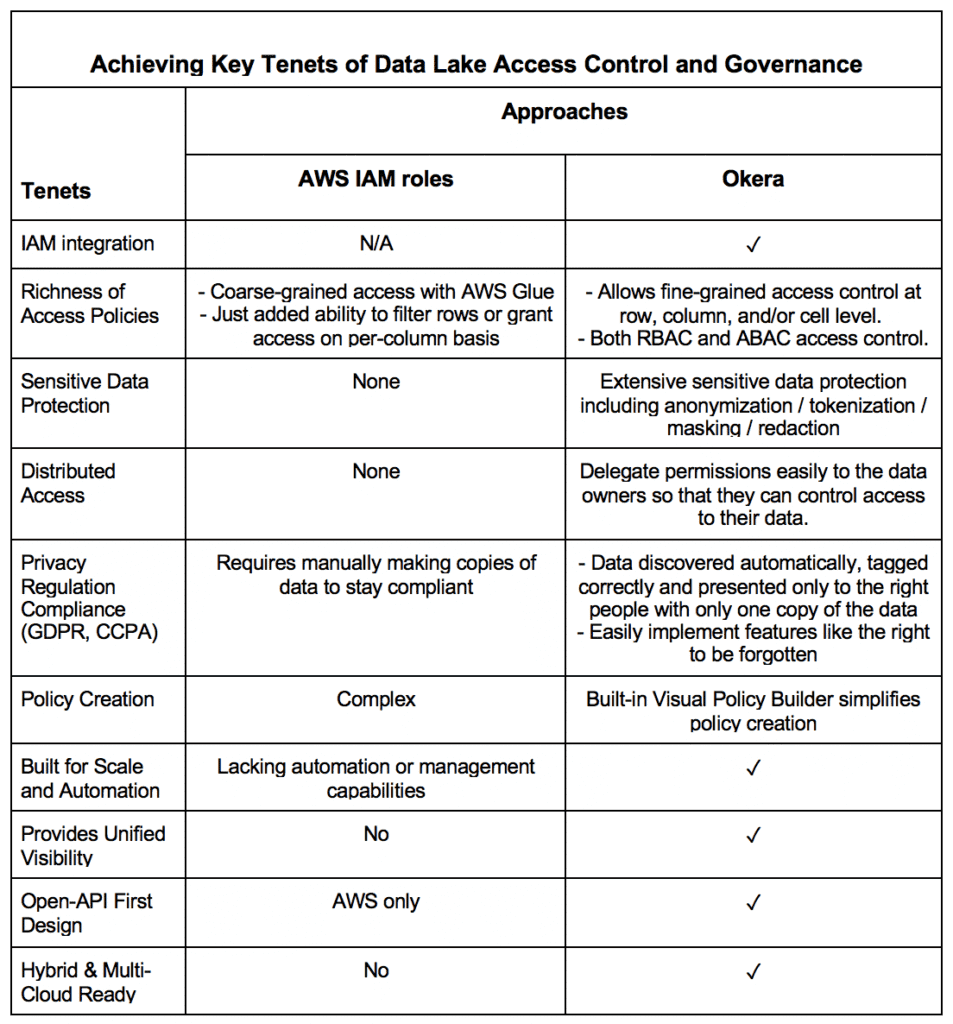
IAM and Okera: A Comparison