Consistent Policy Enforcement
Okera enforces data access policies so companies can use confidential, PII, and regulated data responsibly.
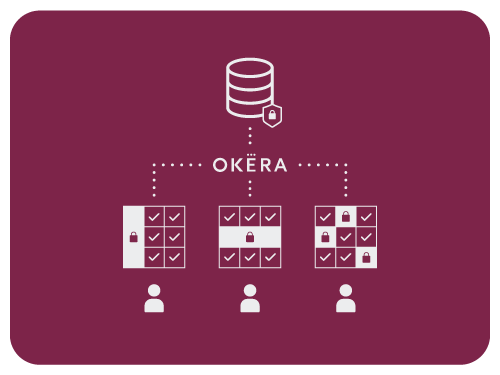
Enforce Data Access Policies
Policies without enforcement are just words on a page. Okera manages all the heavy lifting behind the scenes.
Multiple enforcement patterns make sure policies are enforced consistently across your cloud data warehouse, data lake, and lakehouse platform.

What Does Data Policy Enforcement Look Like?
Okera data policy enforcement is transparent to the user. When a user issues a query, such as select * (“show me everything”), Okera determines which columns and rows the user is authorized to see, and in what format.
For the same query, for example:
- A data steward might see all data in-the-clear
- A sales analyst might see PII tokenized or masked, and filtered by country
- A sales director sees all PII in-the-clear but filtered for his territory
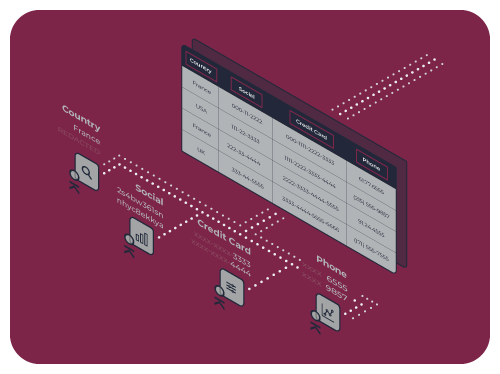
Okera Does the Heavy Lifting Behind the Scenes
Okera makes it easy for you to develop platform-agnostic data policies. Behind the scenes, Okera chooses the best way to enforce your policies.
Okera optimizes for performance and handles platform complexity so you don’t have to.
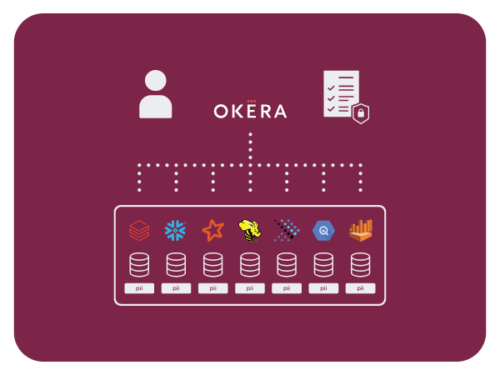
Okera’s Foundational Enforcement Patterns
Okera developed platform-specific enforcement technologies.
At the highest level, they can be understood as falling into one of two fundamental patterns.
Not on the data path
Okera tells the data platform how to enforce policies:
- Native Policy Sync (e.g. Snowflake)
- Query Rewrite (e.g Databricks)
- Security as Views
On the data path
Okera enforces policies and forwards authorized data for analytic processing:
- nScale for Amazon EMR (Spark, Hive, Presto)
- BI Gateway (other JDBC/ODBC)
Native Policy Sync
Modern data platforms such as Snowflake Data Cloud have first-class data access and security controls, such as column, masking, and row level policies.
Okera policies synchronize into these data platforms.
Policies are authored and managed externally in Okera, but enforced natively, entirely within the data platform itself. Okera never touches the data.

Query Rewrite
Query rewrite can be implemented in several ways. For Databricks, Okera plugs into the Spark driver and integrates into the Hive Metastore.
Okera provides metadata-driven instructions to Spark. Spark rewrites queries so only authorized data is returned – filtered, masked, tokenized, etc.
Databricks plans and executes all queries. Similar to Policy Sync, Okera never touches the data.
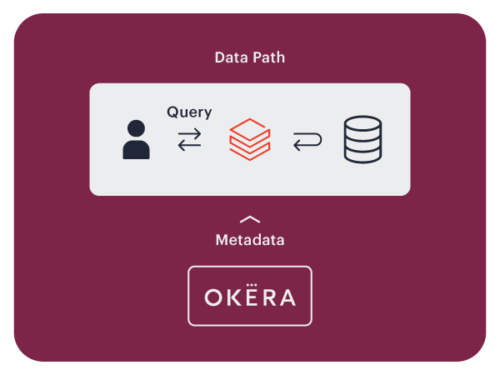
Data Access Isolation
Open big data platforms present unique data security challenges that are not easily addressed with native integrations.
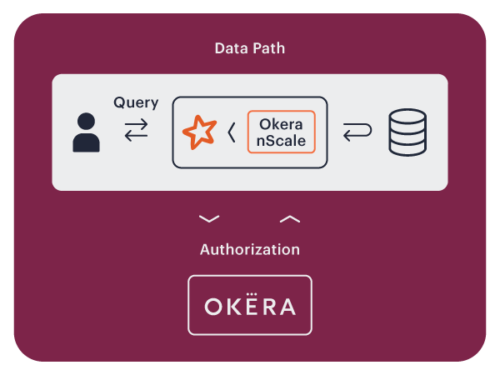
In open environments like Amazon EMR, Okera uses the data access isolation enforcement pattern.
Okera uses nScale, which is our high-performing, distributed data security layer for open big data environments. Okera nScale co-locates with popular compute frameworks such as Spark, Hive, and Presto as an isolated process. Co-location assures consistent performance even under heavy load and extreme elasticity.
Policy enforcement happens in Okera nScale. The Okera Policy Engine delegates nScale temporary and exclusive access to S3 buckets, preventing arbitrary user code from accessing your data lake. Okera nScale filters and transforms data according to the Okera policy and sends clean data to the compute framework for analytic processing.
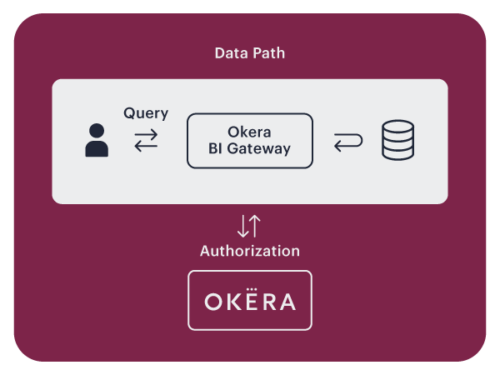
Reverse Proxy
When using a reverse proxy, clients connect to an Okera BI Gateway with JDBC/ODBC. Okera receives, authorizes, and rewrites queries to enforce data access policies.
Data flows through the Okera BI Gateway. Reverse proxies are a convenient way to enforce data access security, but are less suitable for big data compared to other Okera enforcement patterns.
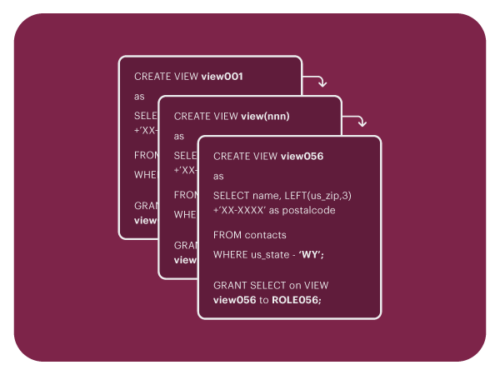
Data Security as Views
Okera supports security as database views. However, like other modern data platform leaders, Okera generally discourages “security as views” in favor of modern Policy Sync or another Okera enforcement pattern.

From the Snowflake documentation
View explosion and corresponding role bloat are undesirable, as anything that makes data security harder to implement and maintain is undesirable. Okera’s other enforcement patterns are preferred for easier management and faster query performance.

AIRSIDE 2022 KEYNOTE
In this informative and entertaining keynote, Doron Porat shares her team’s experience building an open data platform and sets out a vision for the future.
Learn how Okera can audit and analyze sensitive data usage
Satisfy financial audit committees, CISOs, data protection officers, and more with self-service sensitive data usage intelligence.