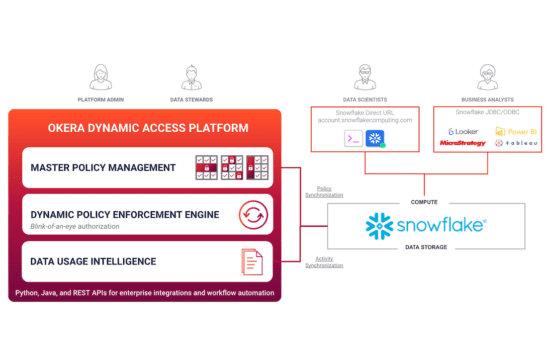
As I prepared to write this blog about Okera’s latest release, it seemed almost disingenuous not to acknowledge all the things that have changed in our world – and continue to change almost every day – due to the COVID-19 pandemic. Data privacy and the importance of safeguarding sensitive data are on people’s minds in a very different way than a few months ago. Okera’s CEO Nick Halsey recently shared his thoughts on how to balance our privacy and healthcare needs in the age of COVID-19.
As states and countries began to issue their “safer at home” orders, companies of all sizes were suddenly forced to find ways to enable remote work, whether or not they already had the necessary infrastructure to do so. This has already led to an uptick in cybersecurity incidents. Because of this unfortunate reality, we foresee another tremendous shift on the horizon, wherein organizations will move from being purely reactive into a more forward-thinking mode where they consider how to make these digital transformations long-lasting and successful.
As more and more enterprises build out their data platforms to enable this digital transformation and take advantage of the cost-savings promised by cloud computing, they inevitably face the challenge of scaling out access to their data in a way that is both secure and provides the maximum flexibility to respond to changes.
Typically these goals have been seen as being at odds with each other, with the implication that choosing one meant sacrificing the other. However, we at Okera have always believed it shouldn’t be a choice; that putting data security at the heart of your business will ultimately enable you to be more agile and ultimately more successful in the long run.
Today I’m excited to announce Okera’s 2.1 release that extends our attribute-based access control functionality to support specifying policies with privacy and de-identification functions. This will give organizations more granular control over how they provision access to their data and simplify the process of policy management, resulting in increased business agility and flexibility.
We believe that attribute-based access control is a powerful and necessary building block to scale secure data access across the enterprise. Role-based access control (RBAC) solutions seem to work well enough at the beginning, when only a few business units and use cases need to be managed. But as more and more users, applications, and datasets are onboarded, with use cases that require more granular access control with data transformations in order to be compliant, RBAC becomes painful and difficult to manage, often turning into “role explosion.” This results in the data platform team becoming the bottleneck preventing the organization from fully utilizing their data, when in fact their mission is to enable the use of data.
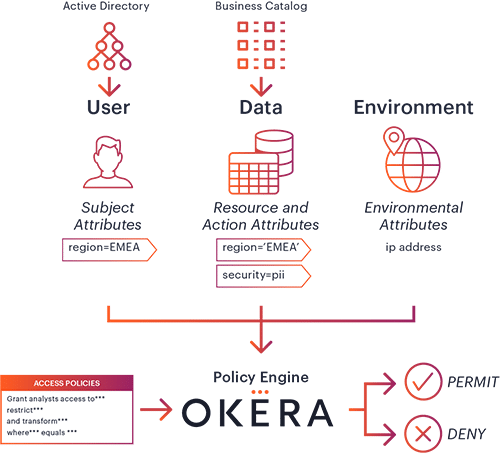
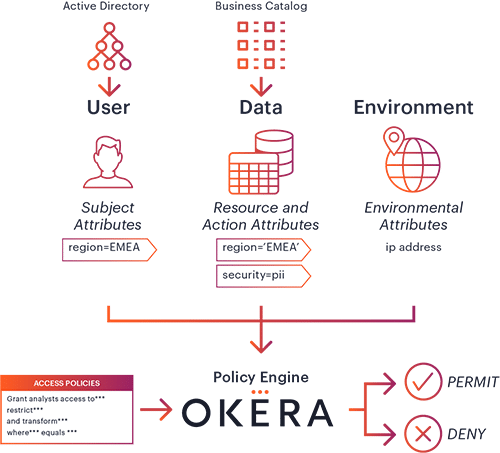
Attribute-based access control (ABAC) enables organizations to define flexible access policies by leveraging multiple attributes – information about the user, the data being accessed, the location etc – in order to make a context-aware decision regarding each individual request for access. Combining ABAC with Okera’s powerful dynamic enforcement of privacy and security functions, as well as an intuitive no-code user experience to define and manage these policies, is a critical step toward scaling access control across the enterprise.
Extending ABAC to include De-identification
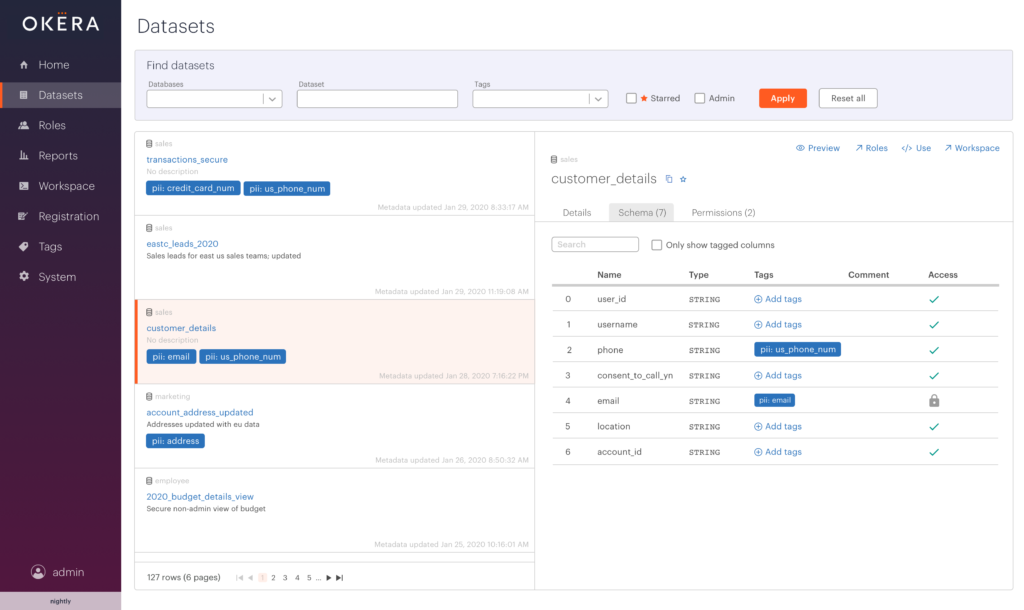
Last year, we added the ability to leverage ABAC for column-level access – granting or restricting access to columns tagged with personally-identifiable information (PII) such as credit card number or IP address. In 2.1, we’re building upon that functionality to support the use of ABAC for more granular access control such as row- and cell-level, as well as sophisticated de-identification and privacy functions like dynamic data masking and tokenization. Our customers can also expand their access control policies with custom user-defined functions (e.g “All users should be able to see data only from their region, and only Director-level or above should see unmasked financial data”).
Thanks to our API-driven design, the Okera platform can leverage attributes from other systems such as Active Directory, or the business metadata and attribute classification that live in enterprise data catalogs like Collibra. This allows the data stewards to define and manage their policies based on the richest, most comprehensive set of knowledge the enterprise has about their data and their users.
No-Code Policy Definition for De-identification
Even leveraging the power of ABAC, most enterprises are slow to respond to change in the regulatory environment, whether from external legislation such as GDPR, CCPA, the NY SHIELD act and others, or simply the organization’s own data privacy policies. That’s because the people who understand regulations and the data the best – the non-technical data stewards, or governance and privacy professionals – have to partner with IT in order to define and manage policies.
In most cases there’s no real feedback loop that allows them to understand whether their policies are actually being enforced. This makes organizations’ response to changing regulation a very slow and cumbersome process, and ultimately ends up hurting the analysts and data scientists who need access to the data, which contributes to the damaging perception of added security as causing friction.
Thinking about managing policies at scale, one key pillar is a simple and intuitive user experience to define and manage these policies. In 2.1, we’ve extended the capabilities of our visual policy builder to make it very easy to create policies with privacy and de-identification functions. Policies involving data transformations such as masking and tokenization, attribute-based access control (ABAC), and row filtering can all be created in the policy builder, without writing any code. This will allow non-technical data owners and stewards the ability to manage policies with incredible granularity.
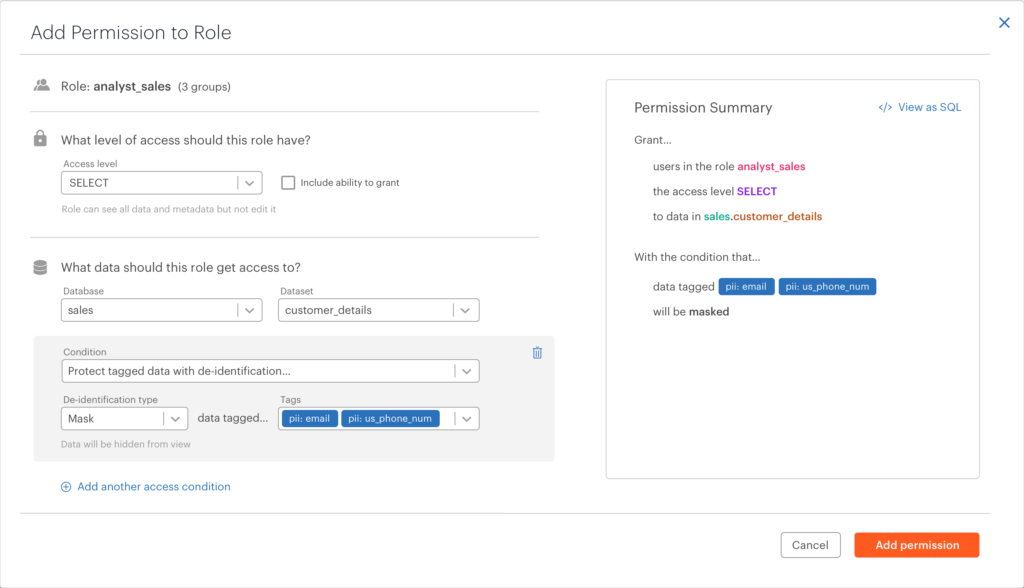
Our customers have gained incredible speed and flexibility with how they can respond to changes in regulation, governance standards, or enterprise access policies. Since Okera enforces policies at runtime, the analysts don’t need to stop working if a policy needs to change; the next time they run a query against a dataset whose permissions have changed, they will only be able to see what they are permitted to see.
Any policy enforcement layer sitting between storage and compute runs the risk of becoming a bottleneck, and ultimately reduces the benefits of using such distributed engines in the first place. That’s why we architected Okera’s dynamic policy enforcement to look more like those distributed engines than a relational database. Our platform is fully containerized and horizontally scalable, allowing us to serve customers with petabyte scale data lakes.
Let’s see what this looks like in practice:
User Inactivity Reporting
One of the main things driving our product vision is the goal of making data stewards’ and governance teams lives easier. Our platform will do the heavy lifting, surfacing key insights that they can then use to take action.
From partnering with our customers, we began to hear the same use case coming up again and again. Data stewards at large organizations must perform monthly or quarterly access reviews, where they look at how often a user has accessed certain data and then remove those who aren’t actively using their data access within that time frame. For example a common case where users maintain more access than they need is when they change roles within the company.
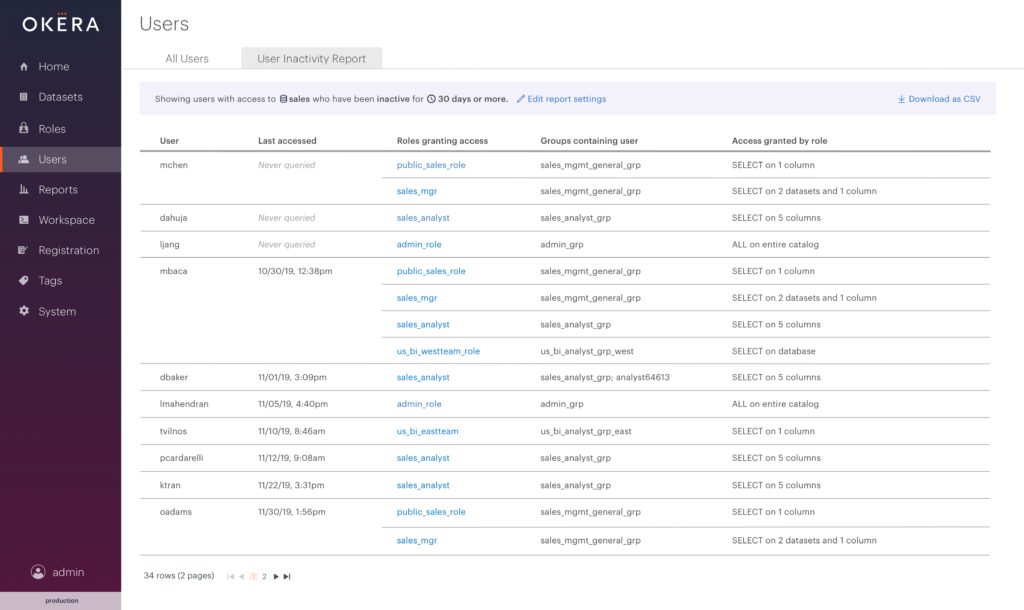
With Okera’s comprehensive audit logs and reporting dashboard, we already answered the question “Who has actually accessed this data?” Our roles page also helped data stewards answer the question “What roles can access this data?” What was missing was the insight that comes from knowing who sits in that area of overlap – users that have access to some data and are not using it. This represents the least privilege risk within the organization.
Our User Inactivity Report makes it simple for data stewards to receive a list of users who have not been active on data they have access to for a specified time period, generated with only a few simple clicks.
Let’s hear some more about how it works:
Okera’s 2.1 release is now available to new and existing customers. We’re excited to deliver these powerful new privacy and security capabilities to help enterprises enable self-service analytics and unlock the full potential of their data.
To learn more about how ABAC with dynamic enforcement is the key to scaling secure data access through the enterprise, watch this on-demand webinar.