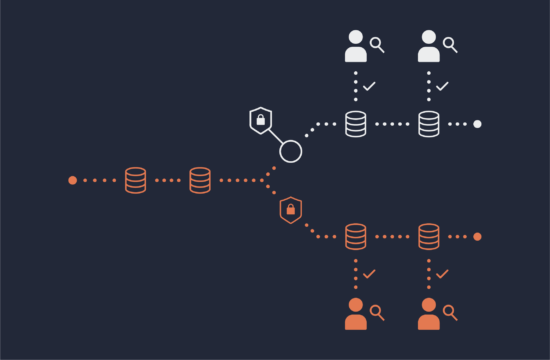
One question we get from prospects evaluating our software is whether or not we provide a full data catalog service. This is an important question and requires that we first define what types of metadata are relevant for data lakes and data access solutions. Okera deals primarily with two types: technical metadata and business metadata.
What is Technical Metadata?
Technical metadata defines technical attributes that are necessary for data presentation, manipulation, and analysis, such as data type, field length, content profiling, lineage, and more. Okera sits on top of raw data sources – object and file storage systems (like Amazon S3, Azure ADLS, or Google Cloud Storage) as well as relational database management systems via JDBC/ODBC, streaming and NoSQL systems. Therefore, we primarily focus on the technical metadata, in order to organize the various data sources and their attributes. This includes information such as:
- Data Source – Since Okera supports a plethora of low-level storage systems, this set of attributes will record the original source system, along with relevant accompanying information such as the software version, connection string, network endpoint(s), chosen source format type, and drivers needed for data access. These are shared across multiple datasets and usually defined at a higher level.
- Credentials – For external systems, it may be necessary to define the access credentials centrally in Okera so that it will access data on behalf of the user. This may include JDBC/ODBC username and password, or IAM credentials (LDAP user info, Kerberos principal and keytabs, etc).
- Location – This is usually a file/object path (for example s3://foo-bucket/data/table1), or a table name reference to the underlying database system (like salesdb.transactions-q4-2020). Location maps a specific source, like a directory or table, into the Okera Schema Registry as a dataset object.
- Mapping – Sometimes translation is necessary to bring information from the original source system into Okera’s technical metadata catalog. This can include field mappings or other details needed to establish a data exchange path between the two systems.
- Schemas – Onboarding datasets into Okera is essentially a pure metadata operation; defining datasets that can be discovered and used by the downstream applications and clients. Schemas store the logical structure of the dataset, including the table properties and columns with their names, data types, etc.
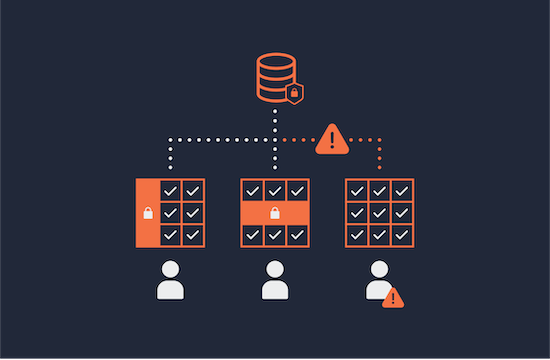
- Attributes – Objects at any level can be tagged with attributes that are used for classification purposes, or as part of the access policies. For instance, you can tag a column containing birthdays with the attribute pii:birthday and then define a policy that would deny direct access to that column, unless the user has been granted express permission to see that tag.
Technical metadata is all about physical attributes that help to load data from the original sources. It enables systems such as Okera to not only gain access to the data, but be able to transform it on-read into the defined schema and deliver it securely to clients.
What is Business Metadata?
Conversely, business metadata is concerned with giving data meaning in the context of the organization. This could include information such as:
- Ownership – Modern data-centric organizations employ a distributed data stewardship process where lines of business (LOBs) are responsible for managing their data on their own. A catalog needs to track that ownership so that interested parties can find and request access to data as part of their business tasks.
- Classification – Finding data, often called data discovery, is one of the most important tasks that business metadata can support, using attributes to classify the data source. It utilizes centrally defined corporate ontologies, taxonomies, and knowledge graphs, as well as machine learning technologies such as recommendation engines, to enable business clients to find interesting data objects.
- Relationships – Like in a technical dataset schema, business metadata also maps the relationships between objects in the catalog, (like the relationships between databases, datasets, and their columns). In contrast to technical metadata, the order of columns is not important here; only the fact that, for instance, a column named crcd16 is a child of sales_eu_q3_2020.
Business Semantics Management (BSM) in an enterprise includes tools and methodologies to organize the business metadata so that ambiguities are kept to a minimum. For example, the column crcd16 mentioned above, what is really stored in it? Instead of tagging the column object with freeform attributes such as “credit_card” or “CCN”, using the proper classification lets users identify catalog objects containing credit card data using a single, approved attribute name – for instance, pii:creditcard.
Technical & Business Metadata – Bridging the Gap
There is some obvious overlap between technical metadata and business metadata. Classification and tagging with attributes especially are down for data discovery, but also to protect data from prying eyes. An attribute such as pii:birthday is clearly needed for both business and technical purposes.
Cataloging software at the enterprise level applies to all kinds of information, not just technical sources. For example, you may have a file server that provides access to scanned copies of customer-submitted forms. If the form asked for the customer’s birthday, you would certainly want to tag these files with pii:birthday. In other words, a business catalog often allows users to find all data sources, whether structured or unstructured, that contain a certain type of information. The technical metadata to access such sources is likely a subset of what the larger data catalog solution offers.
If you’re only dealing with structured data sources being consumed by analytics tools for reporting or business intelligence, a pure technical catalog is often sufficient. You can also bridge the gap by connecting the two systems for a data exchange in either direction, or bi-directionally, as needed, using common REST-based APIs (since this is metadata and therefore relatively small).
With proper strategy and scripting, it is possible to keep both technical metadata and business metadata in sync. That way, tagging could be done in the business catalog, where the ontologies are maintained, then synced to the technical catalog, which automatically enforces the access policies based on the present user and object attributes.
Discovery and Classification of Technical and Business Metadata
Another interesting topic is discovery of the data. Sometimes this is interpreted as the process of, for example, finding all datasets that have sensitive data in them. But more holistically, discovery happens even before that – when data is actually found in the deluge of data sources.
Imagine the above examples, including network filers, databases, streaming sources, etc. How do you actually tag the metadata of those sources so users can easily find them? Traditionally, this was a time-consuming process where each data source was onboarded manually, checked by a data steward for its qualification, and then published in the catalog.
Newer systems can now crawl the file system or database and automatically discover possible dataset candidates and their suggested set of attributes. These crawlers don’t just look at the sources and metadata like file names, but also scan the data and apply machine learning models to identify sensitive information and suggest proper tagging.
Both the business and technical catalogs have an interest in doing this, though for different reasons. While the business catalogs want to classify the data according to organizational rules, the technical catalogs want to be able to apply the proper security policies as they enable their users to quickly consume new data sources. But as discussed above, the discovery process could be executed in either one.
However, the case could be made that technical systems are better suited for this process at scale, as their enforcement layer is already built for massive-parallel-processing (MPP) and deploys as a scalable cluster. That may or may not be true for business metadata management systems.
Understand, Manage and Secure Your Business’s Data
In summary:
- Technical metadata is concerned with the physical and security-related aspects of the available data sources.
- Business metadata is concerned with the organizational aspect of the available data sources, helping to structure and classify the information.
- While technical metadata is likely to be a subset of an enterprise data catalog, in some cases, a technical catalog with some business semantics may be sufficient.
- Enterprise data catalogs can be synced with the technical catalog in the enforcement layer.
- Examining the actual data to discover its metadata helps to streamline the onboarding of new data sources, which at scale requires a parallel processing architecture.
Okera’s Active Data Access Platform is one such scalable platform that can cover a wide range of use cases. We also partner with the leading enterprise data catalog vendors and look forward to discussing your specific technology stack and use cases.