
In 2008, I spent a year getting around Seattle, Washington with a bright orange 1976 SuperBeetle. Apart from its strong performance in snow, I remember its engine: the air-cooled design had few moving parts and remarkably, could run on either alcohol or propane. The engine’s low price, durability and most importantly, modularity, made it an uncanny industrial success beyond its intended use. Today, an industry of conversions continues to repurpose that original Beetle engine into air compressors and aircraft engines.

Your correspondent’s 1976 Super Beetle
We can see the same winning combination of low-cost, durable, modular technology repeat itself with Amazon S3 and cloud data storage. Over the last decade, we’ve seen a large share of enterprise data migrate to Amazon S3 because it has happened upon the same kind of value. While organizations were first drawn to the savings of storing data in the cloud and the benefit of geo-redundancy, adding Amazon S3 support to Hadoop required contributors to develop adapters and new commit protocols to manage the impedance mismatch between file system semantics and the object store. Once analytical tools supported Amazon S3 however, a new vanguard of re-use emerged; one in which OLAP compute logic is decoupled from the storage interface. One immediate advantage? The freeing of storage to support the exponential growth in data happening at the time. Most importantly, Amazon S3 ’s abstractions exposed methods that operate on objects, with no schema-on-write requirements, making it possible to build a number of state of the art ML and analytical workflows, against any kind of data, but with the same storage mechanism.
Since then, organizations have built out their data at large scale, leading to data lakes of massive heterogeneity composed of data from different lines of business. This practice lends itself to a natural interleaving of sensitive and non-sensitive data. In the past, I’ve seen organizations move their data warehouses to Hive or Presto over an Amazon S3 data lake, only to face the problem of data governance and security. The combination presents a new complexity: how to grant access to data scientists and analysts who are eager to extract business intelligence while simply restricting access to sensitive data. Fortunately, Okera’s ODAP platform provides exactly this solution for modern enterprises. Okera performs automatic classification of data and provides a single policy engine presiding over fine-grained access control for data everywhere: Amazon EMR, data warehouses, RDBMS. In the case of Amazon EMR, Okera has two important features:
- The first is that Amazon EMR now becomes as least-privileged as it gets. The resources and hosts in the Amazon EMR cluster are granted no access to Amazon S3, supporting a zero-trust architecture for multi-tenant systems. More specifically, the Okera policy engine will provision temporary credentials to users so organizations can take advantage of the flexibility and power of Amazon EMR over an Amazon S3 data lake, protecting it with Okera’s consistent and dynamic application of access control.
- The second, is the nScale architecture, wherein the Okera component responsible for I/O with Amazon S3 doesn’t reside in the Okera cluster, but is deployed to Amazon EMR core hosts to scale with the compute engine.
Introducing file based access control
To date, Okera’s Amazon EMR integration has supported workflows pertaining to relational data. Data stewards or managers could create cross-cutting ABAC policies defining access to a particular table or subset of a table, which opened up access to Presto, Hive or Spark queries against the sub-set of the table that is non-sensitive. But, as I argued above, Amazon S3 supersedes the data warehouse in the way its interface can interchangeably work with clients which analyze any kind of data, structured and unstructured. In many of those cases, users need to access their data as an object or file, rather than as a set of partitions coalesced into a logical table by the Hive metastore and manifest files. For that reason, we have found a broad need to unlock more potential of the data lake. So, we built OkeraEnsemble.

OkeraEnsemble, now in beta for Spark and boto3 (including the AWS CLI ), makes secure Amazon S3 access like this possible. AWS users are still able to maximize their Amazon S3 clients; amplified by Okera‘s access control, which is applied to grant/deny access to the data itself.
Consider the last example above, a data steward could be moving data with the AWS CLI between s3://myorg/one-year/survey and s3://myorg/seven-day/survey. For example, using the AWS CLI tool:
aws s3 mv –recursive s3://myorg/one-year/survey s3://myorg/seven-day/survey
The manager could be running this command on a host where they have no permissions to access Amazon S3 . Once their AWS CLI configurations are updated, this Amazon S3 call will be granted, or denied read access from the source, and write access to the destination, via the Okera policy engine. This means that the same policies the data steward or their organization have setup with Okera will govern the access control of moving this data via the AWS CLI. Likewise, Spark integrates with OkeraEnsemble to provide access control to all of the tasks across the cluster’s executors reading partitions from a specific Amazon S3 path.
val dataFrame = spark.read.parquet("s3a://myorg/sensitive-data-path")
How it works:
To free the upgrade path for Amazon S3 clients, Okera avoided extending implementations of Hadoop’s FileSystem or the Amazon S3 Clients themselves. Instead, OkeraEnsemble deploys a lightweight proxy which emulates Amazon S3’s endpoint. Integration with the Amazon S3 clients is done through discreet plugins written to the client’s plugin interface.
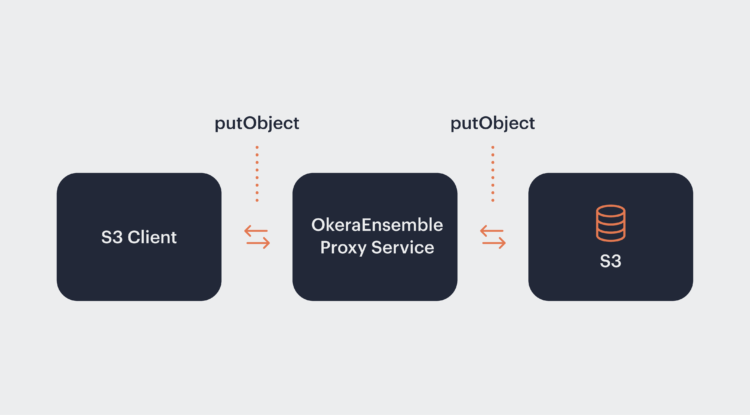
OkeraEnsemble Proxy service
In the case of a standard Amazon S3 client making a method call, say putObject, the client will traverse its ordered chain of ‘credential providers’ until it finds AWS credentials associated with the user or host: environment variables, configurations, IAM role, etc. It will then use several request headers, and the user’s secret key, to generate an HMAC signature using the AWS v4 signer. The client will then attach the signature to the request as the Amazon authorization header, after which the Amazon S3 services will validate the signature against the content of the request to ensure it was not modified in transit.
With OkeraEnsemble, the Amazon S3 client, say boto3 or Spark, is provisioned with an Okera plugin. Since users are likely running commands where they have no credentials to access Amazon S3 directly, the provisioning configures an AWS Credentials Provider for the client, and changes its default endpoint from east-1a.amazonaws.com to the OkeraEnsemble proxy DNS entry. When a user calls an Amazon S3 method on the client like putObject, the client signs the request with the Okera-provided AWS credentials sent to it by the credentials provider. The OkeraEnsemble proxy will use the credentials from the request to authenticate the user to Okera, and perform the same validation of the request. Let’s consider the following example, in which OkeraEnsemble is integrated with the AWS CLI in default mode, where the Okera Proxy is deployed within the Okera ODAP cluster.
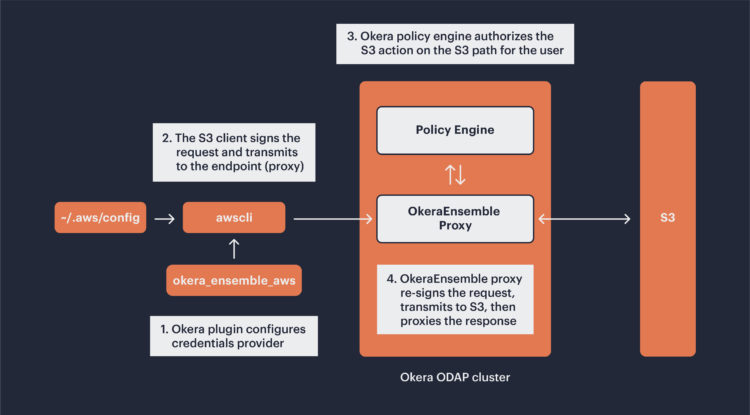
OkeraEnsemble file read/write, integrated with AWS CLI, default mode
Next the proxy will authorize, via the Okera policy engine – the Amazon S3 action on the URI the user is attempting. If successful, the proxy will re-sign the original request with ODAP’s Amazon S3 credentials and send the request to an Amazon S3 endpoint. Okera follows its standard procedure of logging each access attempt in its audit logs. If authentication fails, or the Okera policy engine does not authorize the user that action on that URI, the request returns to the client with an HTTP response code set to 403; Access Forbidden.
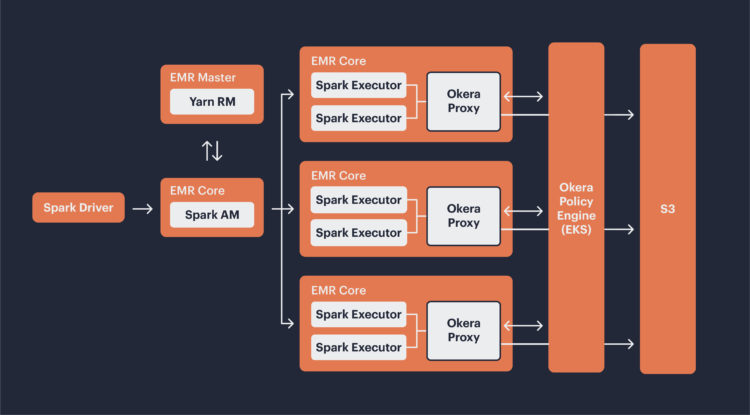
OkeraEnsemble nScale integrated with Amazon EMR Spark
Spark integration with OkeraEnsemble mostly follows the same sequence. The only change is that the Amazon EMR host provisioning will configure the Spark Executor Amazon S3 Clients with a custom credentials provider. In the nScale system shown below, the Okera Proxy service is deployed to each Amazon EMR Core, so executors will also be configured to route their Amazon S3 requests to localhost. The proxy will authorize each request through the Okera Policy Engine.
Performance:
Amazon EMR frameworks are able to delegate table scans to Okera’s secure Enforcement Fleet services. These crucial I/O components have been the subject of engineering focus from ODAPs inception. They are put to the test daily by enterprise customers with data lakes on the petabyte scale. Visit Security Doesn’t Need to Slow You Down to learn more.
Okera’s nScale architecture supports distributing load across more of these workers in a way that is elastic to the scale of the Amazon EMR cluster. The OkeraEnsemble proxy components scale with the same mechanism, so a set of Spark executors on an Amazon EMR host route their read and write requests to Amazon S3 via a local OkeraEnsemble proxy service. The proxy makes use of authorization caching on both the proxy and policy engine side.
Conclusion:
The best governance and data security solutions should take the same versatile approach as Amazon S3 . OkeraEnsemble was built to be extensible to most Amazon S3 use-cases and is drop-in ready over Amazon EMR. When data security is done right, it must be capable of presiding over the whole organization’s data in order to be comprehensive, simple and effective. Okera’s centralized metadata and policy engine defines policies once and extends them to all of your data in Amazon S3 and beyond for a single powerful solution.



