What is a Database Schema?
Database schemas are a representation of how all your data is stored and organized. Schemas are important for understanding the relationship between data and how it can interact and be accessed. Database schemas are essential when creating new data storage systems, in order to ensure that data is securely stored, but is also organized and actionable. It also determines the format of data that is being stored, as well as assigning the identifying keys used to locate and retrieve it. Schemas also help to visualize complex data systems, as they are being designed and implemented.
Database schema design is an important part of achieving successful data organization and optimal data management. Data organization is a vital performance optimization technique proven by use in legacy data warehouse architectures, where it is common that data is stored in accordance to its use case. For example, transactional data is stored in a row based format, where each row represents a transaction record. In contrast, analytical data is commonly stored in columnar form; organized by facts and dimensions across many separate tables.
This happens mostly due to physics, as storing and processing bytes is an inherently restricted task. That is, once you have laid out data within a physical storage medium, it is costly to rearrange it. Row-based, single table access is great for point operations (e.g. “Load the details for order 123”) while columnar and multi-table access is good for reporting (e.g. “What was the revenue in North America in October by retail stores”). If there was a single way to physically store the data so that both access patterns could be served efficiently, the need for use-case based storage techniques would be unnecessary. But in reality, this is impossible as each data layout, or schema, is bound to its use-case and will likely perform poorly for the other.
The Importance of Database Schema Design
In the world of big data, this dilemma is still applicable. Data still resides on storage media burdened with the same hardware related caveats. The end result is that enterprises have no be-all-end-all solution for storage and processing needs, but still employ a large gamut of dedicated systems for particular use-cases. The most prevalent examples are RDBMSs for transactional data, data lakes for historical data and analytical workloads, and streaming systems for near-realtime processing.
All these disjointed systems leave data consumers with the challenge of combining the different sources of data at query time. Combining these datasets requires users to map each individual source into a schema to represent a common structure for all datasets in the query. Having schemas allows users to join those sources on shared attributes, such as customer number or order ID.
One Database Schema Format and One Schema Registry
The Okera Platform provides a single Schema Registry to define database and dataset schemas using common SQL commands. Each record in a dataset is divided into fields to represent each of the columns in the relation. Since many users will already be familiar with database management, SQL is a practical choice to provide the necessary functionality to define and administer these schemas. With all of these available data sources, how do you approach the task of defining these schemas?
How to Design Database Schema
The most straightforward approach to defining schemas is mapping underlying data source into a SQL TABLE object with each attribute matching the original schema. A developer or analyst could then use the resulting table to feed dashboards or be a part of complex queries using the SQL JOIN operator as they would with any other SQL table. For the data owners, this approach defines a one-to-one mapping from the data source into the Okera Platform, thus allowing data consumers to immediately begin using their data.
But this also raises two kinds of questions: A) What about inexperienced users who do not know how to interpret the raw field names? What about new colleagues who need to consume the data, but are not familiar with the original data source? And B) What happens when you face schema drift, that is, the underlying raw data layout is changed and now needs to be reflected in the table schema? How can you avoid to expose the structural change of the table to everyone who is using it?
The Alternative: Proxy VIEWs
The questions for B), that is the issue of tables being too close to the underlying data source structure, can be mitigated by wrapping the table into an SQL VIEW. That way, the one-to-one table structure is disconnected from the users, so that low-level changes are only reflected in the VIEW definition. All downstream consumers have to use the proxying view instead of the table, putting them out of harms way (that is, shield them from certain structural changes). Using SQL GRANT statements, the DBA can revoke access to the table and allow access to the view instead.
Eventually, there may be enough substantial changes in the underlying table structure that the view is no longer able to mask without a substantial loss of fidelity. In that case, another VIEW could be defined with a new name to represent the way forward. Those who need to get access to the latest schema can migrate to the new view as necessary.
For questions A), using a view over the low-level table allows the database administrator (DBA) to easily clean up table details (e.g. rename fields, change their types, and fix issues with content). The view then exposes only well known fields with names that are part of the enterprise-wide vocabulary. We call this the cleanup view and we suggest that it be used as the basis for all subsequent consumption.
But come to think of it, there is more you can do with views. For example, you can use them to filter, project, or modify data. These activities are not unusual for DBAs to do and fit right into the context of Okera, leading us to the overall reference schema design architecture.
Database Schema Examples
The primary difference between the Okera Platform and a standard RDBMS is that our platform is designed for efficient data access and control, which is why we rely heavily on SQL commands tailored for those tasks. More specifically, we have removed any analytical features, such as using DISTINCT or GROUP BY operators in order to deliver the most efficient administrative experience possible. What we recommend is adding another layer in the schema design architecture to account for these access controls measures, that is, the access control views.
For that, the DBA needs to define one more view over the cleanup view(s) that does all the necessary work to return the data in the form a particular user would expect to see. Allowed operations are SQL projections and selections, that is, the inclusion of certain columns in the SELECT statement, combined with a WHERE clause that filters what rows are returned. In addition, the DBA can use SQL functions to mask or tokenize column values based on the user running the query.
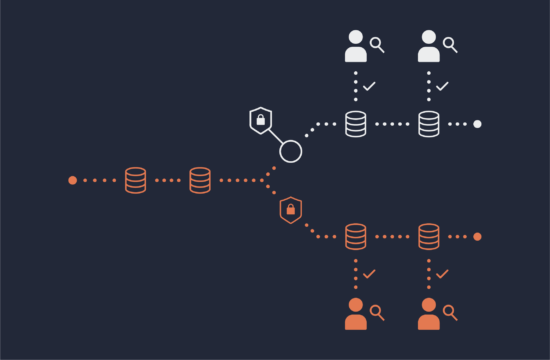
The diagram shows these layers together.

Using access control views gives you the ability to share the same schemas with many users, as their evaluation occurs at query time under the context of the current user. The remaining complex query functions, including computational tasks, are delegated to the downstream processing engines.
Compute Engines
Because of the tailored SQL support, aggregate functions must be handled outside of the Okera Platform in external compute engines. In fact, it is common for users to express their logic in higher language abstractions, such as HiveQL for Hive, Scala or Python for Spark, or SQL for Presto. These engines are now also responsible for the remaining operations to produce the final result for the specific user query.
Okera supports this by allowing DBAs to define special VIEWs that are registered with the Schema Registry, but are not evaluated in Okera. For example, consider this VIEW definition (note that, for the sake of the example, the sales_transactions dataset is assumed to be an access control view):
CREATE VIEW sales_transactions_cal AS SELECT ... FROM sales_transactions WHERE region = 'california'
Usually, when a user query contains such a view, such as
SELECT * FROM sales_transactions_cal the ODAS Planner returns the VIEW as a TABLE definition (that is, it returns the fields in the final schema) when requested by the compute engine. This can be seen when using the SHOW CREATE TABLE command from the Hive CLI (shown abbreviated): hive> SHOW CREATE TABLE sales_transactions_cal; OK CREATE EXTERNAL TABLE sales_transactions_cal( txnid bigint COMMENT '', dt_time string COMMENT '', sku string COMMENT '', userid int COMMENT '', price float COMMENT '', creditcard string COMMENT '', ip string COMMENT '') ...
This leaves the compute engine no choice but to read from that table reference like it is a raw source of data (e.g. an S3 file).
Okera supports the EXTERNAL keyword to define a view that is different from Okera’s default behavior. For example:
CREATE EXTERNAL VIEW revenue_cal AS SELECT min(revenue) as minRevenue, max(revenue) as maxRevenue FROM sales_transactions WHERE region = 'california'
Here we define a view that uses an aggregation function that is not supported by the Okera Platform’s SQL language. The EXTERNAL keyword changes how the Okera Data Access Service (ODAS) Planner returns the VIEW definition when requested by the compute engine, returning the full VIEW definition instead:
hive> SHOW CREATE TABLE revenue_cal; OK CREATE VIEW revenue_cal AS SELECT * FROM salesdb.sales_transactions WHERE region = 'california'
The result is that the evaluation of the VIEW occurs outside of Okera Platform but inside the downstream compute engine. All of the unsupported SQL is handled downstream as well, while the sales_transaction access control view is still handled by Okera; applying all the filtering and audit logging as expected.
Impact and Outlook
You may be asking yourself if defining all of those views over the base table are resource overhead and computationally expensive. Since the Okera Platform is evaluating these layers at query plan time, the answer is a definitive no. The operations of each view over the base table are combined into a single statement, complete with user role-dependent actions. When the query is executed on the ODAS Workers, there is no further cost to the slightly more involved schema hierarchy. Functionally, it is free of any additional cost to the query.
On top of that, the layered view approach in the Okera Platform provides DBAs with additional data management capabilities. For example, it allows DBAs to limit the amount of data returned for a partitioned table when no matching WHERE clauses was defined. The special Okera-provided LAST PARTITION feature can avoid unnecessary full table scans (such as SELECT * FROM to check what data a dataset holds, just to realize it has terabytes or petabytes of data) that may inadvertently choke up valuable system resources.
Okera recommends these guidelines to provide for a future-proof, stress free management of datasets – something administrators and users will certainly appreciate.