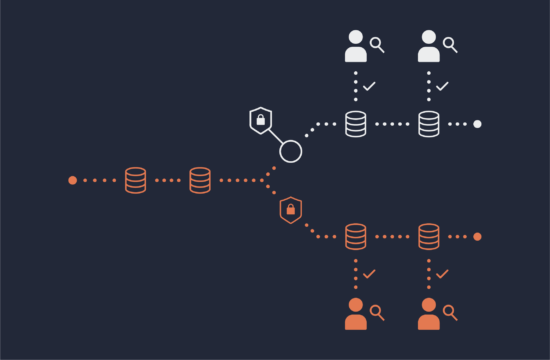
Protecting Big Data Frameworks with a Colocated, Secure Data Plane
This post continues our discussion about how to secure data access on the modern enterprise analytics platform. Previously, we looked at Okera’s proxy pattern, which lets you continue to benefit from any optimizations made to a SQL engine for highly efficient query processing (Hive, Impala, Snowflake, etc) while still enforcing fine-grained access control, regardless of whether the source system supports it or not.
However there are cases where the client does not have the mechanism to natively enforce the access policy, or where enforcing access policies at the “edge” is not secure. Take these two use cases:
- A team conducting analysis on a multi-tenant cluster running Spark on EMR, whose users all have different levels of access to the dataset.
- A data scientist conducting some analysis on sensitive data using Python.
One huge advantage of Okera’s Dynamic Access Platform is that it’s able to choose between multiple enforcement mechanisms, guaranteeing consistency of policy enforcement and a transparent experience to the end users. This blog will be focused on access control enforced through a separate data access service, called Okera’s Adaptive Security Plane…and it comes with a new cutting edge twist!
Okera’s Solution: The Adaptive Security Plane
Okera’s Adaptive Security Plane (OASP) is a highly efficient input/output (I/O) layer written in C++, implementing a massively parallel processing (MPP), shared-nothing architecture where worker nodes independently process the data loading and access control parts of user queries. Because of this design, our data plane can scale to any size needed to handle even the most strenuous workloads. Our customers securely process petabytes of data and trillions of rows every day with ease.
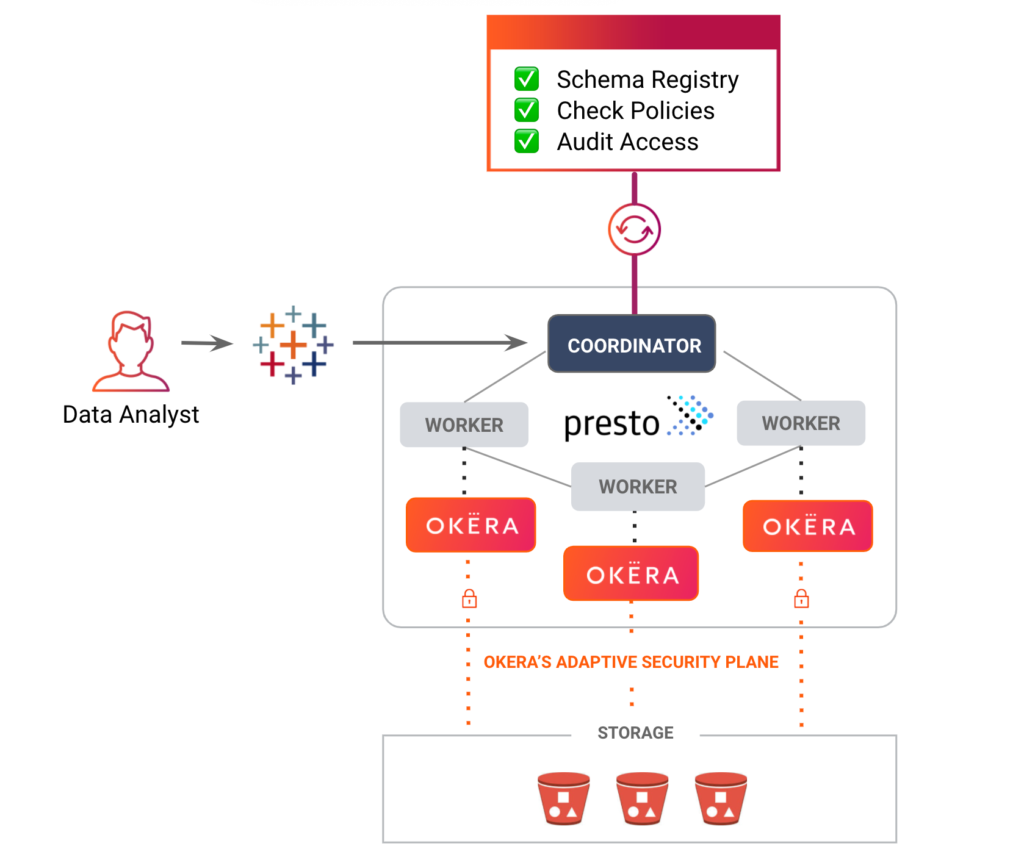
Query engines like Presto, Spark, etc can use our Adaptive Security Plane to efficiently load the data and apply all policies (such as transformations and filters) to it. All without needing to give the query engine access to the underlying data, which allows for fully secured access.
That sounds great, you might be saying, but what about:
- Performance – If my data is traveling through another layer, isn’t that going to add overhead?
- Scale – How do I ensure a transparent and consistent user experience, especially for seasonal or ad-hoc workloads?
- Security – Do I still need to manage complex IAM roles for all my VMs? How do I ensure that no one can get direct access to the data (e.g. via SSH or custom code)?
We discuss performance in depth in our “Security doesn’t slow you down” blog post, but in short – building a scalable secure data plane is no small feat. For many reasons, we believe that the Okera Adaptive Security Plane is the best in the industry.
Adaptive Security Plane at nScale
When it comes to scale and security, that’s where our twist comes in: Okera workers can co-locate for compute engines like Spark, Presto, and Hive. We call this deployment mode nScale, for infinite scale, because it provides perfect elasticity. Instead of having to maintain dedicated servers for the secure data plane and each of the compute engines, you can run OASP as a separate, isolated process on the same nodes as the compute engine is using.
Let’s see how this applies to the use cases mentioned above.
Multi-tenant Spark on EMR with no IAM
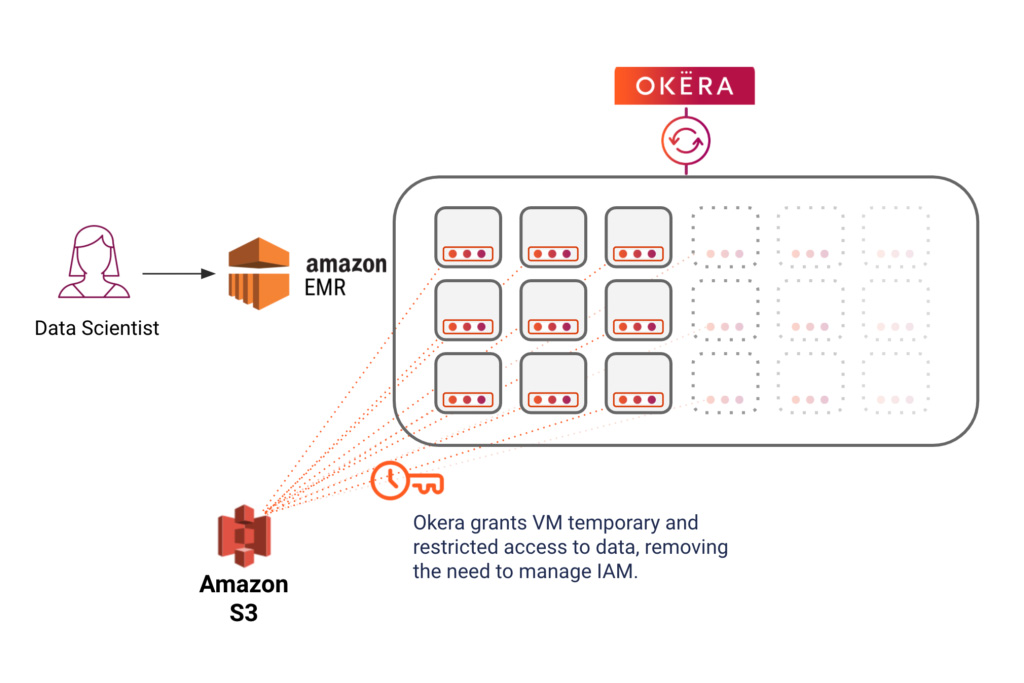
The diagram below shows how a big data cluster – in this case Amazon EMR – has been provisioned with the Okera worker processes. This EMR cluster can share with the Okera metadata services, which can be used by multiple clusters. When the cluster scales up or down, so do the Okera worker processes – completely automated and transparently. This reduces the marginal cost for the Okera worker to nearly zero.
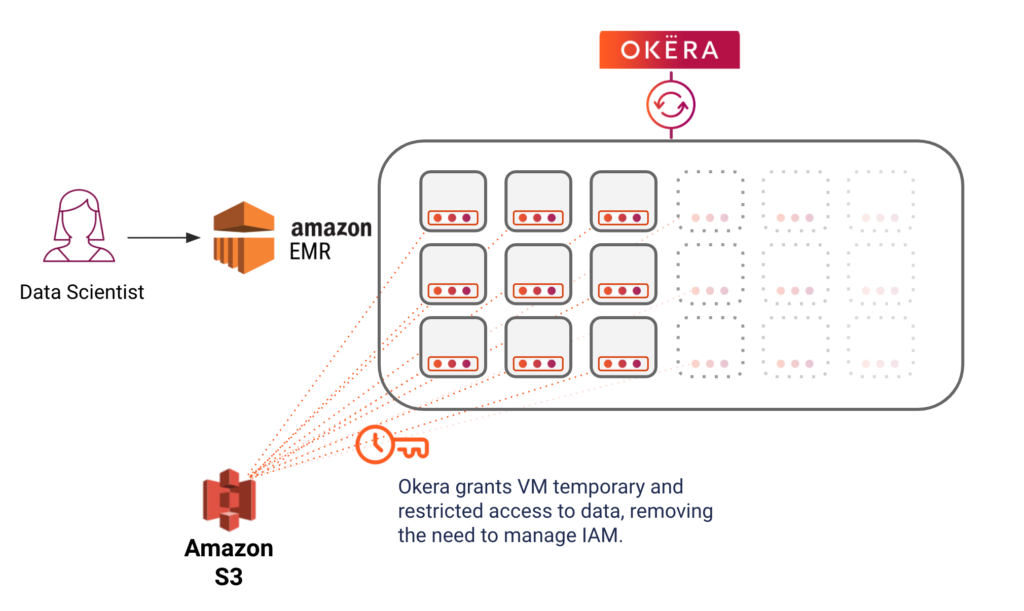
But doesn’t that machine still need access to the underlying data? No, because Okera’s Adaptive Security Plane, in nScale mode, is able to grant the Okera workers temporary and specific access to the data. This ensures that the enforcement layer is properly isolated from the compute engine, as there are no VM-wide data access permissions and the Okera workers only get access to the data needed for a specific query in an ephemeral and restricted way.
This means that an organization can stand up an EMR cluster running Okera’s Adaptive Security Plane with nScale, without managing any IAM privileges on that VM. Multiple users can interact with that EMR cluster, just like they do today, and be securely authenticated through Okera. When a user runs a query, Okera will authorize the request and then, running co-located on the same nodes as the EMR cluster, securely accesses that data through a temporary credential, sending only the secure and transformed data (e.g. joins, aggregations, etc) back to Spark.
Data scientist running Python
Python has consistently emerged as the most popular language among data scientists due to its versatility and support for a variety of libraries and frameworks. However, Python is not a distributed query engine, and analytics teams struggle to enforce policies on data being accessed through Python. This results in data scientists often being granted full access to sensitive data through their machines, exposing the organization to inadvertent and often unaudited risk. With Okera, this whole process becomes seamless.
Let’s take a data scientist running Python on their Domino Data Labs cluster, with Okera’s Adaptive Security Plane in nScale mode. Once again, IT teams no longer need to manage individual IAM permissions to the underlying files; instead, OASP securely retrieves the underlying data, applying any transformations or filters as per the access policies, and surfaces only the correct data back to the Python server.
In addition, data scientists can leverage the PyOkera library, which not only provides seamless authentication to Okera through Python, but makes it much easier for data scientists to interact with technical metadata and to provision data into a data frame.
Benefits
Let’s quickly recap the benefits of Okera’s Adaptive Security Plane with nScale:
- Perfect elasticity at zero cost: OASP deploys on existing compute infrastructure and scales along with it, reducing operational and infrastructure cost to near zero. This eliminates the possibility that security will cause a bottleneck and ensures a seamless experience for your end users.
- Secure and isolated enforcement layer, no need to provide IAM access: Deploying OASP with nScale provides temporary access only to the data that is needed to execute a particular query, without exposing that access to the rest of the system (even the compute engine!).
- Consistent policy enforcement and auditing for open big data frameworks: Your users get to leverage the best open source big data and analytics frameworks, and you get unified policies and audit logs, even for systems that don’t traditionally have this support.
In Summary
Organizations are looking for a truly unified access solution, “a single policy consistently and securely enforced across all analytical workloads.” Having a secure data plane to enforce policies that can’t be enforced either natively or securely by the client is a critical part of that story.
This is one of the many reasons that Okera is the leader in providing secure data access to any data at enterprise scale. You get the flexibility of being able to integrate in the best possible manner for each individual use case, while getting state-of-the-art data security features and unified access with a single place to manage all your analytical data.
If you have more questions, please contact us to learn how we can help you build an enterprise-grade access control layer for your company. And look out for the next installment of this blog series on the many ways to secure data access with Okera!